
AI-Worker – oder auf gut Deutsch KI-Arbeiter – verwandeln generative KI von einem Spielzeug und einer Nischenanwendung in einen echten Produktivitätsfaktor. Werfen wir einen genaueren Blick darauf, wie das funktioniert und wie es die Art und Weise, wie wir Geschäfte machen, grundlegend verändern könnte.
Ein Brief der CEOs
Im Januar diesen Jahres trafen sich die CEOs der größten Unternehmen der Welt in Davos. Ein Schlüsselsatz, den wir immer wieder von diesen Führungskräften hörten, war, dass wir im Jahr 2024 nicht nur über KI diskutieren, sondern endlich Plattformen mit echten Auswirkungen implementieren werden: Diese KI-Plattformen werden die Art und Weise, wie wir arbeiten, forschen, Kundendienste anbieten und Umsätze generieren, grundlegend verändern. Fast jeder CEO versprach, im Jahr 2024 massiv zu investieren.
Nun ist klar, dass das Jahr 2024 bereits in vollem Gange ist. Zu diesem Zeitpunkt können wir die Fortschritte der KI bewerten:
Hmm. Äh. Aha. Abgesehen von den Technologieunternehmen hat sich also noch nicht viel getan.
Sicher, klar, jeder nutzt ChatGPT und Co., um Briefe, Artikel und Beiträge zu schreiben und Python-Funktionen, Bilder und Videos zu erstellen. Und es gibt eine Unzahl neuer Chatbots im Kundenservice. All das hat das Potenzial, die Produktivität zu steigern – um, sagen wir, 3 %. Vielleicht sogar 5 %. Und das in der gesamten Wirtschaft.
Super. Super. Echt super.
Aber weit davon entfernt, weltbewegend zu sein.
Warum ist das so? Warum hat die KI noch keine größeren Auswirkungen?
Weil die KI noch nicht bereit ist?
Nein! Weil wir nicht bereit sind.
Wir setzen sie falsch ein!
Die bereits erwähnten Zwei-Gig-Anwendungen – Alltagsassistenten und First-Level-Support – sind nützlich und wichtig, aber sie werden die Art und Weise, wie wir Geschäfte machen, nicht grundlegend verändern.
Der Löwe im KI-Zoo
Werfen wir einen Blick auf die Geschichte der KI-basierten Systeme für Angestelltenaufgaben und schauen wir, was sie leisten können.
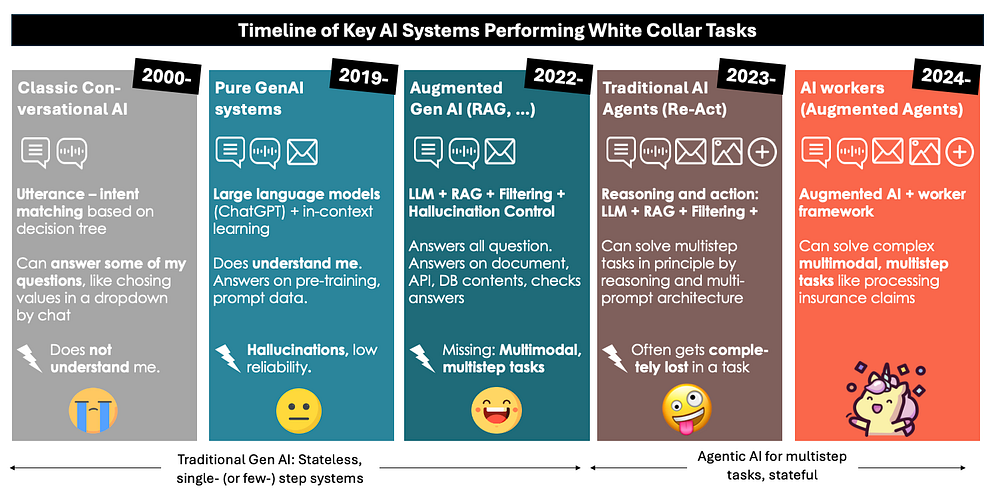
Eine kurze Anmerkung zu den klassischen, pre-generativen KI-Systemen (conversational AI-based utterance-intent matching). Diese Systeme sind zwar immer noch im Einsatz, werden aber heute nicht mehr gebaut. Das sind die Assistenten der alten Schule, die einen in der Regel nicht verstehen, weil sie im Grunde jede Frage und jede Antwort von Menschen geschrieben bekommen müssen. Sie werden von Menschen am Telefon angeschrien und mit Gewalt bedroht. Die schlechtesten aller Bots. Wirklich.
Bei den genAI-Systemen sind viele nur noch als augmented genAI verfügbar – weil sich die reinen genAI-Systeme aus der engeren Auswahl relevanter Anwendungen „heraushalluziniert“ haben. Interessant ist, dass augmented genAI-Systeme Halluzinationskontrolle und RAG nutzen können, um Benutzerfragen zuverlässig auf der Basis von Dokumenten, Datenbanken und APIs zu beantworten. Ich habe einige dieser Systeme selbst mitentwickelt: Sie sind großartig. Punkt. Zumindest im Moment noch.
Eine kleine, aber entscheidende Einschränkung für die augmented genAI-Systeme: Sie können nur kleinere Aufgaben lösen: das Beantworten von Nutzeranfragen, Klassifizieren und Extrahieren von Dokumenten, Verfassen von Antworten, etc. All diese oben erwähnten Gig-Jobs.
Die meisten Angestellten arbeiten anders: Wir arbeiten stunden-, tage-, wochen-, manchmal jahrelang an einer einzigen Aufgabe. Wir können durch komplexe und vielschichtige Prozesse navigieren, um ein bestimmtes Ergebnis zu erreichen. Wir sind es gewohnt, auf eine Antwort eines Kunden oder eine Entscheidung des Chefs zu warten und können die neuen Informationen dann nahtlos in eine Aufgabe integrieren. Unsere Aufgaben bestehen nicht darin, „die Frage eines Benutzers zu beantworten“, sondern eher folgende:
- Algebra in Klasse 4 unterrichten
- Einen Unfallfahrer vor Gericht verteidigen
- Planung und Durchführung einer Marketingkampagne für ein neues Produkt
- Optimierung der Logistikprozesse in unserer Lebensmittelabteilung
- Optische und inhaltliche Überarbeitung einer Website
- Bearbeitung aller eingehenden Versicherungsansprüche
- Senkung des Stromverbrauchs der Beleuchtung in unseren Büros
- Erstellung eines Angebots für eine komplexe Anfrage
All diese Prozesse können nur durch eine Vielzahl von Einzelaktivitäten erreicht werden, die aus der Klassifizierung, Extraktion und Generierung von Informationen bestehen. An dieser Stelle kommt die agentenbasierte KI ins Spiel. Im Prinzip geht es um Agenten / Arbeiter, die ein Ziel über viele Schritte hinweg verfolgen können. Sie können tagelang warten und über ein Projekt auf dem Laufenden halten. Sie können auch mit verschiedenen technischen und menschlichen Gegenspielern kommunizieren, um die erforderlichen Daten zu beschaffen.
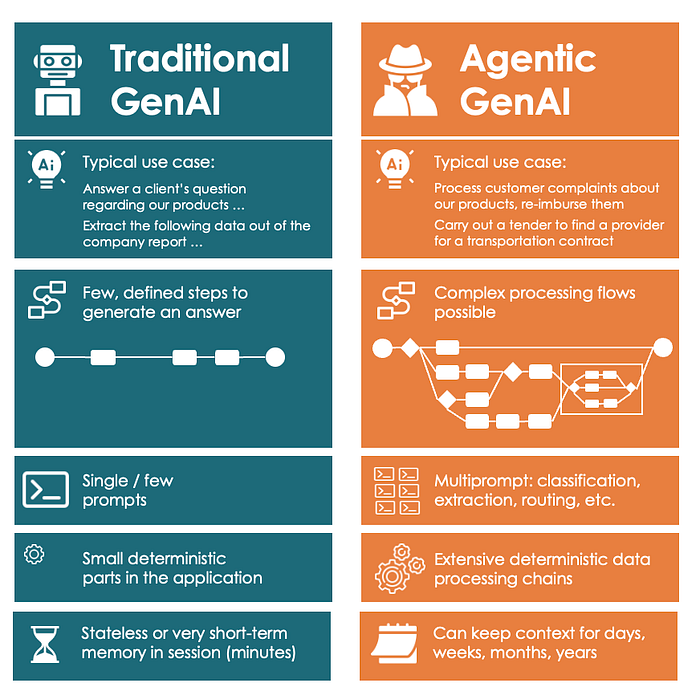
Die Grashüpfer und die Ameisen: KI-Agenten der ersten Generation vs. AI Worker
Natürlich gibt es nicht nur eine Form der agentenbasierten KI, sondern mehrere. Ich werde mich hier auf die beiden bekanntesten und wichtigsten konzentrieren:
1) Grashüpfer: Die KI-Agenten der ersten Generation, die so genannten „ReAct-Agenten“, sind in ihrer Aufgabenbearbeitung völlig frei, d. h. man kann sie mit praktisch allen Aufgaben betrauen. Sie planen zunächst eine bestimmte Aufgabe (z. B. „Stoppt den Klimawandel“, „Zerstört die Welt“, „Plant eine Geschäftsreise nach Singapur“) und führen dann die einzelnen Schritte (z. B. Flugplanung oder Abendgestaltung) selbst aus, wobei sie Modellabfragen, API-Abfragen und Websuchen durchführen, die sie zur Beschaffung oder Generierung der Daten benötigen. Die Idee ist cool und kommt der AGI (Artificial General Intelligence) sehr nahe.
2) Ameisen: Wir haben dafür den Begriff AI Worker geprägt. Die AI-Worker haben im Vergleich zu den Agenten einen viel kleineren Problem- und Lösungsraum. Ein Arbeiter kann zum Beispiel ein verlorenes Paket leicht finden, aber er kann keine Stellenanzeige aufgeben und dann die Bewerber bewerten. Ein anderer Arbeiter könnte dies jedoch, da jeder Arbeiter spezialisiert ist und einem vordefinierten Plan folgt, der vom Product Owner vorgegeben wird. Dies gibt ihnen eine Art Rahmen, eine Art Exoskelett, in dem die Verarbeitung stattfinden kann.
Auf den ersten Blick sind die Grashüpfer faszinierender als die Ameisen. Aber nur auf den ersten Blick: Das Traurige daran ist, dass die ReAct-Agenten überhaupt nicht funktionieren. Abgesehen von vielleicht amüsanten Testfällen, liefern sie kaum aussagekräftige Ergebnisse. Ein Grund dafür könnte sein, dass sie beim Abarbeiten der einzelnen Schritte immer größere Fehler aufbauen. Derzeit sind die freien KI-Agenten der ersten Generation das agentische Gegenstück zu den GPT-2-Modellen. Man kann diese Technologie nicht wirklich für Geschäftsanwendungen nutzen. Aber nach GPT-2 kommt GPT-3. Vielleicht werden wir die Backpropagation über einen kompletten Agenten-Workflow zum Laufen bringen. Das könnte die Erstellung von Arbeitsabläufen zu einer trainierbaren Aufgabe machen. Ich hebe mir das für Ende 2025 auf.
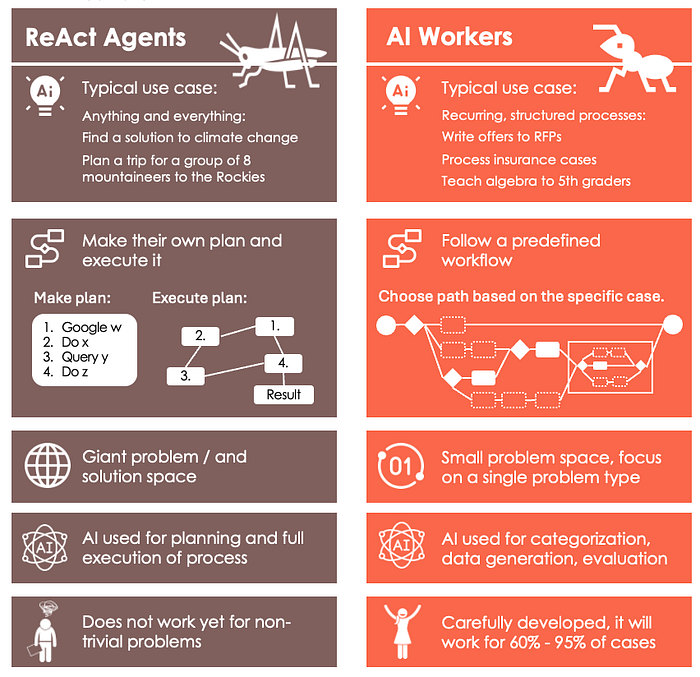
Aber wie arbeitet ein KI-Arbeiter?
Das Verrückte daran ist: Der KI-Arbeiter arbeitet wie ein professioneller menschlicher Angestellter.
Stellen Sie sich vor, ein Kunde meldet einen Versicherungsanspruch an: „Hallo, in unserem Haus hat es stark geregnet, und Teile des ersten Stocks wurden überschwemmt und beschädigt. Hier ist …‘ Der KI-Arbeiter überlegt nicht, wie er das Problem selbst lösen kann. Stattdessen folgt er einem strengen, vordefinierten Verfahren:
- Er liest die E-Mail des Kunden und sieht sich die Anhänge wie Rechnungen und Schadensbilder an.
- Er erstellt einen Anspruch.
- Er prüft, ob es sich um ein Duplikat handelt.
- Er prüft, ob der Kunde bei seinem Versicherer versichert ist.
- Er prüft, welche Versicherung der Kunde abgeschlossen hat.
Und so weiter. 15 -20 Schritte. Mit jeweils 3-5 Teilschritten.
Der Arbeiter geht streng nach den Anweisungen seines Unternehmens vor. Er setzt seine Intelligenz beim Auswerten der Dokumente, beim Extrahieren von Informationen, beim Klassifizieren und Bewerten ein, also in den einzelnen Teilschritten. Der Gesamtprozess bleibt für ihn immer derselbe. Er ist nur ein Arbeiter.
Nun könnten Sie denken … das ist doch langweilig! Die KI könnte doch kreativ sein und einen eigenen Ansatz zur Lösung des Problems finden. Ja, das könnte sie. Aber das ist weder das, was wir brauchen, noch das, was wir in den meisten Fällen wollen. Nicht einmal bei menschlichen Sachbearbeitern.
Wir wollen, dass der menschliche Versicherungsangestellte und der KI-Arbeiter nach einer Reihe von definierten und transparenten Regeln handeln, denn …
- Wir handeln in Übereinstimmung mit Verträgen und Vorschriften.
- Wir vermeiden oder minimieren Kundenbeschwerden.
- Wir sparen Geld und erstatten nur berechtigte Ansprüche.
- Wir haben einen konsistenten, reproduzierbaren, überprüfbaren Prozess, der durch Software unterstützt werden kann.
Der Sinn des KI-Arbeiters ist nicht, dass er das Problem besser oder kreativer löst, sondern zuverlässiger (z. B. keine Tipp- oder Transkriptionsfehler) als ein Mensch. Und vor allem: viel, viel schneller und billiger.
Und genau so funktionieren 70 % unserer Angestelltenjobs: Wir lösen Probleme, aber ohne den Problemlösungsprozess für jeden einzelnen Fall neu zu erfinden: Wir folgen Lehrplänen, Verfahrensanweisungen, Entwicklungsmodellen, Betriebsanweisungen, Gesetzen und Vorschriften. Wir erwecken sie für einen bestimmten Fall zum Leben. Und DAS ist es, was der KI-Arbeiter für uns tun kann. 100x schneller als jeder Mensch.
Aber wie sieht ein KI-Arbeiter aus?
Den ganzen Artikel habe ich hier veröffentlicht.
Folge mir auf Medium oder LinkedIn für Updates und neue Geschichten über generative KI und Prompt Engineering.