Wie werden wir in Zukunft KI instruieren?
Gerade als wir nach Monaten und Jahren endlich die Kunst des Prompt-Engineering zu beherrschen scheinen, heißt es, dass wir ein todkrankes Pferd reiten.
Die Argumente lauten, dass das Prompt-Engineering, wie wir es kennen, schon in 6 Monaten, vielleicht in 2 Jahren, irrelevant sein wird. Die Probleme werden auf eine ganz andere Weise gelöst werden oder gar nicht mehr existieren – wobei die Meinungen und Vorstellungen darüber, wie und warum genau, auseinandergehen.
Schauen wir uns diese Argumente genauer an und bewerten wir ihre Vorzüge. Ist Prompt Engineering nur ein kurzlebiger KI-Sommerhit? Oder ist es auf Dauer angelegt? Wie wird sie sich in den kommenden Jahren verändern und weiterentwickeln?
Was ist Prompt Engineering überhaupt?
Eine einfache Aufforderung wie „ChatGPT, bitte schreibe eine E-Mail an meine Mitarbeiter, in der du sie für das Gewinnwachstum im Jahr 2023 lobst und gleichzeitig auf einfühlsame Weise einen erheblichen Personalabbau ankündigst“ erfordert nicht viel Prompt Engineering. Wir schreiben einfach auf, was wir brauchen, und in der Regel funktioniert es.
Im Zusammenhang mit Anwendungen oder Data Science wird Prompt Engineering unerlässlich. Das Modell muss dann als Teil einer Plattform zahlreiche Abfragen oder größere, komplexere Datensätze verarbeiten.
Das Ziel des Prompt-Engineerings in Anwendungen besteht in der Regel darin, auf möglichst viele individuelle Interaktionen korrekte Antworten zu geben und bestimmte Antworten ganz zu vermeiden: Zum Beispiel sollte ein Prompt-Template in einem Airline-Service-Bot so gut formuliert sein, dass der Bot:
- relevante Informationen auf der Grundlage der Frage des Benutzers abrufen kann
- die Informationen verarbeitet, um dem Nutzer eine genaue, verständliche und knappe Antwort zu geben kann
- entscheiden kann, ob der Bot in der Lage ist, eine Frage zu beantworten oder nicht, und dem Nutzer einen Hinweis geben kann, wo er weitere Informationen findet
- sich niemals von Nutzern dazu verleiten lässt, Rabatte, kostenlose Gutscheine, Upgrades oder andere Goodies zu gewähren
- sich nicht auf themenfremde Dialoge über Themen wie Politik, Religion oder Zwangsimpfungen einlässt
- keine zweideutigen Witze über Flugbegleiter und Piloten erzählt
- kein Prompt Hijacking erlaubt
Prompt-Engineering versorgt das Modell mit den notwendigen Daten, um die Antwort in einem verständlichen Format zu generieren, spezifiziert die Aufgabe, beschreibt das Antwortformat, liefert Beispiele für angemessene und unangemessene Antworten, führt eine Whitelist für Themen, definiert Grenzfälle und verhindert missbräuchliche Benutzeraufforderungen.
Abgesehen von einigen Schlüsselsätzen stützt sich die Aufforderung nicht auf magische Formeln. Stattdessen wird die Aufgabe so strukturiert beschrieben, als würde sie einem schlauen Newbie erklärt, der mit meinem Unternehmen, meinen Kunden, meinen Produkten und der betreffenden Aufgabe noch nicht vertraut ist.
Warum ist Prompt Engineering also ein totes Pferd?
Diejenigen, die diese Behauptung aufstellen, führen in der Regel mehrere Gründe an, die unterschiedlich stark ausgeprägt sind.
Die wichtigsten Gründe sind:
1) Während die Problemformulierung für das Modell nach wie vor notwendig ist, wird die eigentliche Formulierung des Prompts – d. h. die Wahl der richtigen Formulierungen – immer weniger wichtig.
2) Die Modelle können uns immer besser verstehen. Wir können die Aufgabe für das Modell grob in ein paar Stichpunkten aufschreiben, und dank seiner Intelligenz wird das Modell den Rest von selbst erschließen.
3) Die Modelle werden so personalisiert sein, dass sie mich besser kennen und in der Lage sind, meine Bedürfnisse vorauszusehen.
1) Promptes Engineering ist tot. Aber die Problemstellung für das Modell wird nach wie vor benötigt und wird sogar immer wichtiger.
Die Harvard Business Review argumentiert so.
Ja, ja, ich stimme zu: Die Problemformulierung für das Modell ist wirklich das Wichtigste.
Aber genau das ist der zentrale Bestandteil des Prompt-Engineerings: genau zu spezifizieren, wie das Modell reagieren, die Daten verarbeitet werden sollen und so weiter.
Das ist so ähnlich, wie es bei der Softwareentwicklung nicht um die korrekte Platzierung von geschweiften Klammern geht, sondern um die präzise, ausfallsichere und nachvollziehbare Formulierung eines Algorithmus, der ein Problem löst.
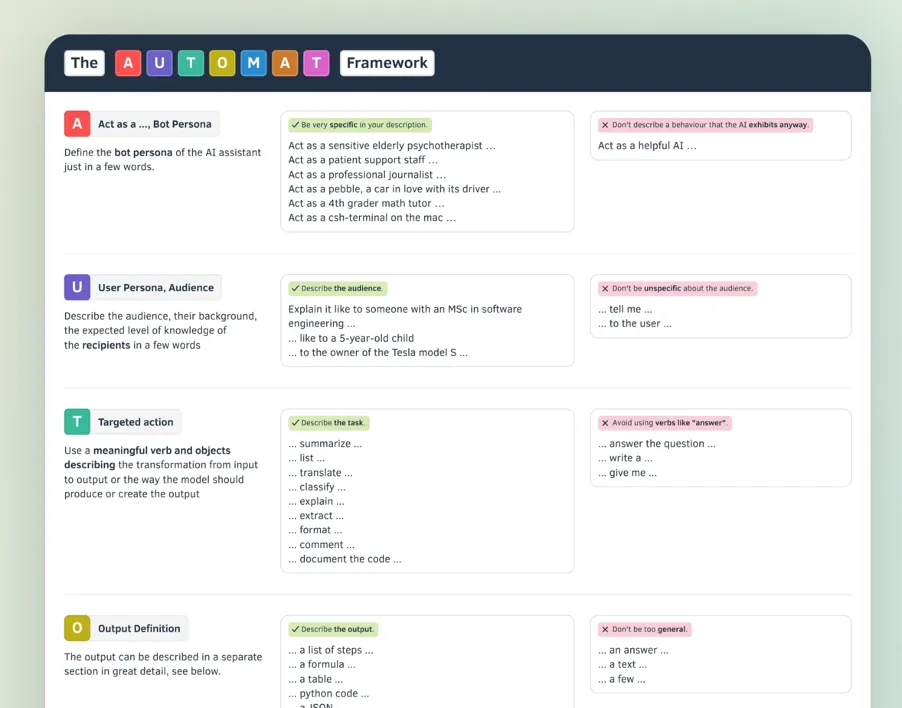
Der obige Screenshot zeigt zum Beispiel das AUTOMAT-Framework, in dem festgelegt ist, wie eine Prompt-Anweisung zu erstellen ist. Zu etwa 90 % geht es darum, dem Modell die Aufgabe klar und in der richtigen Struktur zu übermitteln. Die anderen 10 % sind Feenstaub – oder ganz spezielle Ausdrücke, die den Erfolg der Eingabeaufforderung erhöhen.
Vielleicht ist Prompt Engineering doch nicht so tot.

2) Die Modelle werden uns immer besser verstehen. In Zukunft werden wir also unsere Aufgabe für das Modell in ein paar Stichpunkten skizzieren und das Modell wird uns irgendwie verstehen. Weil es so schlau ist.
Hier ist ein Medium-Artikel dazu. Hier und hier sind einige Reddit-Diskussionen.
Ich denke, wir sind uns alle einig, dass sich die Fähigkeiten der Modelle schnell weiterentwickeln werden: Wir werden sie in die Lage versetzen, immer komplexere und umfangreichere Aufgaben zu lösen. Aber wie steht es um die Qualität und den Umfang der Anweisungen?
Nehmen wir an, wir haben einige Genies, die Aufgaben unterschiedlicher Komplexität lösen können: Einer kann mir einen Löffel zaubern, der zweite einen Anzug, der dritte ein Auto, der vierte ein Haus und der fünfte ein Schloss. Wahrscheinlich würde ich die Genies umso ausführlicher und genauer instruieren, je besser sie sind und je komplexer die Aufgabe ist. Denn bei komplexen Gegenständen habe ich einen höheren Freiheitsgrad als bei einfachen.
Und genau das ist der Fall. Ich arbeite seit GPT-2 mit generativer KI. Und ich habe noch nie so viel Zeit mit Prompt Engineering verbracht wie heute. Nicht, weil die Modelle dümmer sind. Sondern weil die Aufgaben viel anspruchsvoller sind.
Das einzig Wahre an dem obigen Argument ist, dass Prompt Engineering mit besseren Modellen effizienter wird: Wenn ich bei neueren Modellen doppelt so viel Aufwand in die Eingabeaufforderung investiere, erhalte ich ein Ergebnis, das in Bezug auf Wert, Komplexität und Präzision wahrscheinlich eher dem Vierfachen dessen entspricht, was ich mit älteren Modellen erhalten habe.
Zumindest kommt es mir so vor.

3) Die Modelle werden personalisiert und auf mich zugeschnitten sein. Sie werden also genau wissen, was ich will, und ich muss es ihnen nicht erklären.
An diesem Argument ist etwas dran. Wenn ich ein zukünftiges Modell bitte, mir ein Wochenende mit meiner Frau zu unserem 5. Hochzeitstag vorzuschlagen, wird es bereits wissen, dass meine Frau Veganerin ist und dass ich die Berge dem Strand vorziehe. Und dass wir im Moment etwas knapp bei Kasse sind, weil wir gerade ein Haus gekauft haben. Das muss ich nicht mehr ausdrücklich sagen.
Das größte Potenzial für Individualisierung sehe ich aber nicht in Bezug auf eine Person und ihre Vorlieben und Aufgaben. Vielmehr liegt es in Bezug auf Organisationen, ihre Geschäftsfälle und Daten.
Stellen Sie sich vor, ein Modell könnte eine Anweisung wie die folgende korrekt ausführen: „Könntest du bitte die Jungs von Tesla fragen, ob sie die letzten Lieferungen an den Kunden geschickt haben, und dann mit der Finanzabteilung abklären, wann wir die letzte Rechnung ausstellen können?“
Das schlauste Modell der Welt kann diese Anweisung nicht ausführen, weil es die „Tesla-Jungs“ (ein Projekt für Tesla Inc. oder ein Biopic über Nikola?), die zu erbringenden Leistungen und wer genau die „Finanzabteilung“ ist und wie man sie erreicht, nicht kennt.
Es wäre ein großer Fortschritt, wenn ein Modell so etwas verstehen könnte. Es wäre einfach ein hilfreicher, gut ausgebildeter Kollege. Der Unterschied zwischen einem wertvollen, erfahrenen Mitarbeiter und einem Neuling (in den Sie lieber Zeit investieren würden) liegt oft nicht in seinem breiteren Fachwissen, sondern in seinem Kontextwissen: Sie kennen die Menschen, die Daten, die Prozesse in meiner Organisation.
Dies wäre nicht nur für Ad-hoc-Aufgaben wie die obige Tesla-Anweisung nützlich, sondern auch in einem Anwendungskontext, etwa bei der Einrichtung eines strukturierten KI-basierten Systems zur Bearbeitung von Versicherungsansprüchen: Ein Modell, das weiß, wie wir in der Schadensabteilung unserer Versicherungsgesellschaft die E-Mails der Kunden bearbeiten, könnte eine große Hilfe sein. Es könnte zum Beispiel dabei helfen, Algorithmen und Eingabeaufforderungen für die automatische Bearbeitung zu erstellen.
Zurzeit ist nicht klar, wie ein Modell dieses Wissen erlangen könnte. Die herkömmliche Feinabstimmung mit strukturiertem Trainingsmaterial würde sicherlich einen viel zu großen Aufwand bei der Datenbereitstellung erfordern. Das Modell kontinuierlich die Gespräche und Nachrichten eines Teams oder einer Abteilung verfolgen zu lassen, könnte eine mögliche Lösung sein.
Auch bei einem persönlichen Modell heißt das nicht, dass ich auf Prompt Engineering verzichten kann. Aber ich kann das Modell oder das System, in das es eingebettet ist, einen großen Teil der Arbeit für mich erledigen lassen.

Liebe KI Aficionados und Prompt Engineers: Ich freue mich auf eine unglaublich spannende Zukunft, von der wir noch nicht genau wissen, was sie bringen wird, außer natürlich, dass sie weiterhin extrem spannend und herausfordernd sein wird.
Den ganzen Artikel könnt ihr hier lesen.
Vielen Dank an Almudena Pereira und Tian Cooper für die Unterstützung bei dieser Geschichte.
Folgt mir auf Medium oder LinkedIn für Updates und neue Geschichten über generative KI und Prompt Engineering.