Automatisierung (fast) ohne Software-Entwicklung
Wie wäre es, wenn jede Email, jedes PDF mit einem Auftrag, einer Rechnung, einer Reklamation, einer Angebotsanfrage oder Job-Bewerbung in maschinenlesbare Daten übersetzt werden würde? Und dann automatisch vom ERP / CRM / LMS / TMS … bearbeitet werden könnte? Und das ohne Programmierung einer speziellen Schnittstelle.
Klingt wie Zauberei? Hat tatsächlich etwas Magisches. Ist seit kurzer Zeit aber möglich.
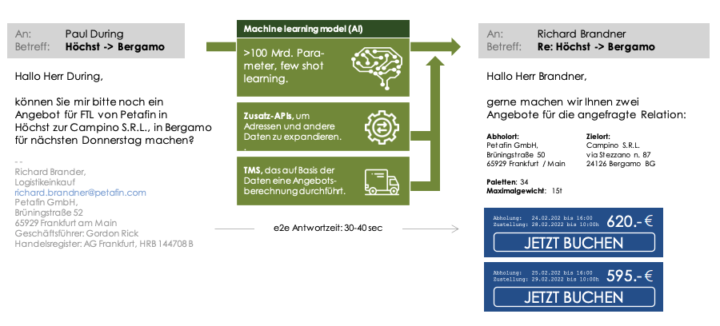
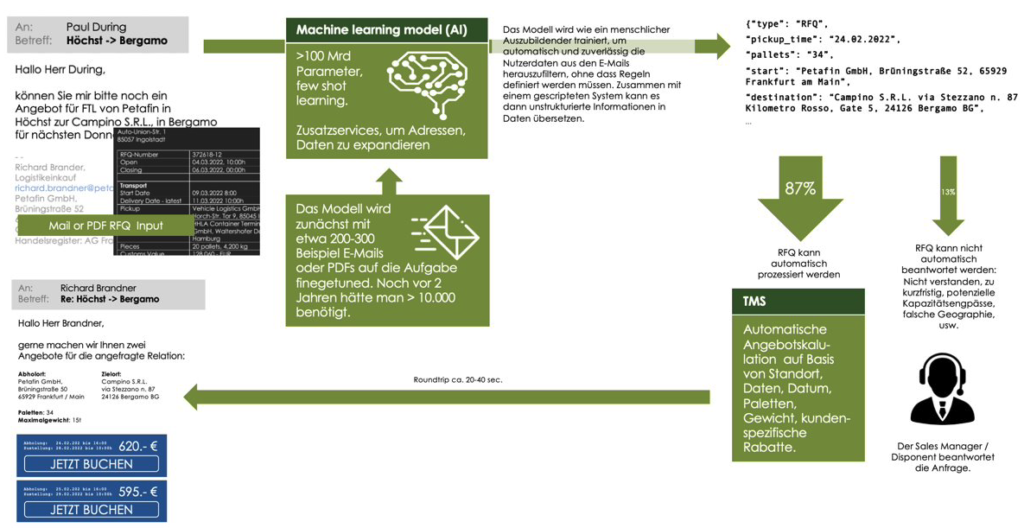
Möglich wird das durch Large Language Models (LLMs). Diese sind – ähnlich wie ein menschlicher Sachbearbeiter – in der Lage, mit keinem oder wenigen Lernbeispielen eine Email in strukturierte Daten umzuwandeln . Die Email, das PDF oder das Dokument wird als Auftrag, als Tender, als Mahnung erkannt. Und die spezifischen Daten werden gefunden und extrahiert. Bei einer Anfrage für einen Transportauftrag zum Beispiel Auftraggeber, Anzahl der Paletten, Gewicht, Ort der Abholung, Zeit der Abholung, Ort der Ablieferung.
Ein zusätzlicher Businessalgorithmus (– das macht nicht das Modell) kann die Anfrage auf Basis der strukturierten Daten dann entweder vorfiltern, direkt prozessieren (z.B. beantworten) oder einem menschlichen Sachbearbeiter als strukturierten Input zur Verfügung stellen ggf. auch mit einem Vorschlag zur weiteren Bearbeitung.
Was sind Large Language Models und warum sollte uns das interessieren?
Die Entwicklung großer Sprachmodelle stellt im Machine Learning der letzten Jahre einen absoluten Meilenstein dar. Die besondere Fähigkeit der Modelle liegt in der Fähigkeit, natürlichsprachlich Fragen zu beantworten, Texte zu erstellen, zusammenzufassen, in andere Sprachen oder Sprachspiele zu übersetzen oder Code zu produzieren – und das ohne Scripting , also ohne einen eigens programmierten Algorithmus, der Userinputs mit Maschinenoutputs verknüpft. Die Modelle produzieren nicht nur syntaktisch (orthographisch, grammatikalisch) korrekten Output, sondern sind auch in der Lage, diffizile sprachliche Aufgaben semantisch korrekt zu lösen. Es gibt eine Reihe LLMs — zu den prominentesten gehören GPT-3 (OpenAI), BERT, T5 (Google) oder Wu Dao (Beijing Academy of Artificial Intelligence), MT-NLG (Microsoft).
Die LLMs zeigen erstaunliche Fähigkeiten in der Beantwortung von Fragen, sowie der Fortführung oder Zusammenfassung von Texten. Ihr Können reicht in vielen Fällen an das eines menschlichen Kommunikationspartners heran oder übertreffen es sogar. Hier sind Beispiele der Fähigkeiten von drei LLMs: GPT-3 davinci, AI21 studio j1-jumbo, Macaw 11B. Keine der Aufgaben wurde spezifisch geübt, keine Antwort ist gescripted. Vielmehr handelt es sich um Beispiele für zero shot Kompetenz: Die Fähigkeit, etwas zu können ohne es spezifisch trainiert zu haben.

Auch strukturierte Daten können generiert werden, z.B. einfache Programme:

Die Modelle sind typischerweise auch in der Lage, andere weit verbreitete Sprachen zu prozessieren, wenn auch keine so gut wie Englisch.

Einige der Modelle können größere Text- / Input-Mengen analysieren und zusammenfassen.

Wie funktionieren die LLMS?
Die LLMs haben alle Fragen (– bis auf die nach der besten Star Wars Folge) richtig beantwortet. Wie machen sie das?
Ein kurzer Ritt durch die Grundlagen der Large Language Models: Die leistungsfähigsten Systeme sind Transformer-Modelle, die im Kern aus einem Deep Learning Modell (einem bestimmten Typ eines neuronalen Netzwerks) bestehen und mit einem Attention-Mechanismus ausgestatten sind. Sie sind in der Lage, sequenziellen Input (z.B. Text) zu verarbeiten und entsprechenden Output zu produzieren. Sie tun das im Kern auf Basis von Statistik: Was ist die wahrscheinlichste Fortsetzung (Antwort auf eine Frage, nächste Äußerung in einem Dialog, Rest eines angefangenen Textes)? – Das heißt sie reagieren nicht auf Basis einer mehr oder weniger festen Zuordnung von User-Intents zu Antworten wie das Siri, Alexa oder andere Sprach-Assistenten derzeit machen.
Die Modelle sind Large in jeder Dimension: Sie bestehen inzwischen typischerweise aus mehr als 100 Milliarden Parameter. Parameter sind vereinfacht gesagt, die Gewichte zwischen den Neuronen, die beim Lernen durch das Modell angepasst werden. Die Modelle wurden mit oft Hunderten von Gigabyte meist öffentlich verfügbarer Textdaten wie Wikipedia und ähnlich großer Corpora trainiert. Die Trainingsinhalte entsprechen im Umfang dem von deutlich über hundertausend Büchern. Um diesen Wert ins Verhältnis zu setzen: In einem Menschenleben gelingt es nur schwer, mehr als 5.000 Bücher zu lesen. Auch der ökologische Fußabdruck dieser Modelle ist immens: Schätzungen zufolge hat das initiale Training des erfolgreichsten LLM so viel Energie verbraucht wie nötig ist, um einmal mit dem Auto zum Mond und zurück zu fahren. Quantität übersetzt sich bei den LLMs z.T. in Qualität. Die aktuellen Erfolge sind auf Basis der Verzehn-, Verhundert-, und Vertausendfachung der Größe der Modelle in den letzten 2–3 Jahren möglich geworden.
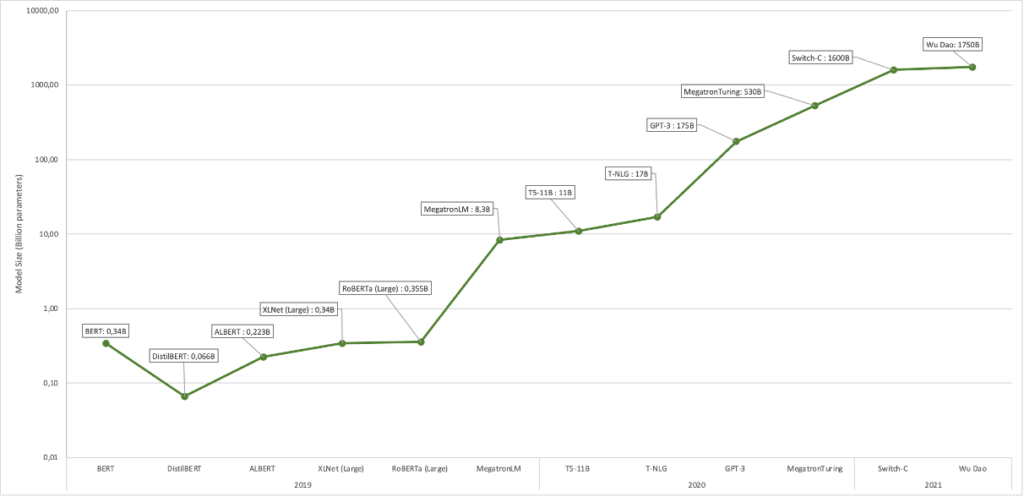
Das Besondere an den neueren LLMs ist, dass sie – wie bei den oben gezeigten Beispielen – ohne aufgabenpezifisches Lernen, Antworten auf Inputs geben können. Ihr Output gelingt lediglich auf Grundlage ihres Basistrainings. Ähnlich wie Menschen sind diese Modelle versatil und in der Lage, aufgrund eines Single-Shot Trainings (einem einzigen Übungsbeispiel), Few Shot Training (ein paar Beispielen) oder sogar ganz ohne Beispiele ein neues Sprachspiel zu verstehen und richtig fortzuführen oder zu beantworten. Das ist revolutionär und neu. Frühere Modelle wurden aufwändig auf genau einen Job trainiert und konnten nur diesen einen bewältigen: Schachspielen, verdächtige Kontobewegungen identifizieren, Gesichter in Bildern finden, etc.
Natürlich ist es trotzdem möglich, auch hier ein Finetuning durchzuführen, d.h. die Modelle mit zusätzlichen Beispiel-Inputs und Outputs auf einen bestimmten Job zu trainieren. Auch das ähnelt dem menschlichen Spracherwerb: Wir können nach rund 20 Jahren Basistraining in Kindheit und Jugend quatschen, streiten, philosophieren, lügen, rechnen, herumspinnen, analysieren oder predigen. Aber um das auf einem hohen und spezifischen fachlichen Niveau zu tun, absolvieren wir Ausbildungen in Jura, Quantenphysik, Buchhaltung, Psychologie oder Theologie.
Limits der LLMs
Die Fähigkeiten der Modelle sind limitiert: Sie zeigen eine eklatante Rechenschwäche bei Zahlen jenseits des Einmaleins. Oft raten sie dann nur noch. Schwierige mathematische Aufgaben lassen sich anders als Question Answering oder Text Completion nicht — wie die Modelle das tun — durch Statistik und auf Basis gigantischer Mengen an Trainingsdaten lösen. Die Modelle machen bei kniffeligen Fragen ähnliche Flüchtigkeitsfehler, die auch Menschen unterlaufen. Ihr Weltwissen bleibt auf dem Stand ihres letzten Trainingszeitpunkts stehen, also z.B. Ende 2019 bei GPT-3. Dazu kommt ihre Unfähigkeit, bei vielen fachlichen Themen abzuschätzen, ob sie da inhaltlich wirklich sattelfest sind und in der Lage, eine korrekte Aussage zu machen. Vor allem dieses Defizit macht eine Überwachung der Modelle notwendig.

Ein spannendes Feld, in dem die Modelle punkten können, ist die Analyse von Texten. Im folgenden Beispiel sagen wir dem Modell, was es tun soll und geben ihm zwei Beispiele: iPhone und Serrano Schinken. Beim Dritten Input (Cider) gelingt es dem Modell selbst, die korrekte Antwort zu liefern (few shot learning).

Auch strukturiertere Daten sind analysierbar . Das folgende Beispiel (wieder mit few shot learning) zeigt eine Art Datenbankabfrage ohne Datenbank und SQL, sondern einfach nur auf Basis der sprachlichen Fähigkeiten. Ähnlich wie das auch ein Mensch könnte.

Ein Automatisierungssetup mit Large Language Models
Wie lassen sich die Sprachmodelle dazu verwenden, unstrukturierte Daten in strukturierte Daten umzuwandeln und automatisch zu prozessieren? Ein Umsetzungsbeispiel aus unserer eigenen Praxis soll das zeigen. (– Wir sind natürlich definitiv nicht die Einzigen, die sich damit beschäftigen, siehe auch dieses Paper).
A. Setup des Modells (POC 1)
Fragestellung: Wir erhalten unstrukturierte Mails ggf. in verschiedenen Sprachen als Angebotsanfrage für einen Transport und versuchen diese in strukturierte Daten umzuwandeln.
Dazu geben wir dem Modell einige Trainingsbeispiele (– das können ein paar Dutzend bis ein paar Hundert sein). Die Beispiele sollten möglichst unterschiedlich sein, damit das Modell die gesamte Bandbreite beherrschen lernt. Die Beispiele sollten auch andere Intents als nur RFQs abdecken: z.B. Nachfragen bezüglich eines laufenden Transports oder Reklamationen, um dem Modell die Unterscheidung der richtigen Klassifikation zu ermöglichen. Die Trainingsbeispiele umfassen die Payload eines Email- oder PDF-Textes sowie die strukturierten Daten, die ausgegeben werden sollen. Alle Daten, die über einfaches Scripting aus der Email gezogen werden können und kein Machine-Learning benötigen, sollten im Vorfeld entfernt werden, z.B. die Absenderadresse oder die Empfänger-Adresse. Der Input sollte auf Basis realer Daten sein, nicht manuell bereinigt, sondern mit Rechtschreibfehlern, umgangssprachlichen Zeitangaben und in allen möglichen Sprachen. Die Ziel-Daten müssen zum Start noch nicht in einem Standformat (JSON, etc.) vorliegen. Die Umwandlung kann wieder über einfache Algorithmen bewerkstelligt werden.

Die Daten werden verwendet, um ein Modell zu schärfen, das dann eingesetzt werden kann, um beliebig viele andere Anfragen zu erkennen und zu bearbeiten.
Welches Basismodell soll für die Anwendung verwendet werden? Die Frage ist nicht einfach zu beantworten, sie kann in mehrere Teilfragen untergliedert werden:
- Welches Modell in welcher Ausprägung, mit welchen Einstellungen bietet die besten Ergebnisse?
- Welches Modell kann ich in meinem gewünschten Operational Setup (Betrieb in eigener Cloud, SaaS-Lösung, etc.) und mit meinen Anforderungen (z.B. Privacy, Datenhoheit) betreiben?
- Bei welchem Modell fallen die geringsten Gesamtkosten (Fixkosten und anfrageabhängigen Kosten) an?
Wenn mehrere Modelle aus Perspektive der Fragestellungen 2 und 3 im Relevant Set sind, sollten diese mit verschiedenen Einstellungen auf Basis erst weniger Trainings- und Testdaten, dann mit vielen verprobt werden, um die optimale Lösung zu finden. Auch der Scope des maschinellen Prozessings kann sich noch ändern, evtl. werden bestimmte Anfrage-Kategorien oder bestimmte Daten nach der Evaluation der ersten Ergebnisse integriert oder wieder herausgenommen.
Wenn das gelungen ist, und eine ausreichend hohe Rate richtiger Antworten für den Business-Zweck erzielt wird, kann zum nächsten Schritt übergegangen werden. Welche Rate genügt, kann je nach Einsatz variieren, es können 60%, 80% oder 98% sein. Wichtig ist, bei der Verprobung Trainings- und Testdaten zu trennen, um Ergebnisse zu erzielen, die im späteren Produktivbetrieb reproduzierbar sind.
B. Einbindung in eine E2E-Gesamt-Lösung (POC 2)
Die Einbindung in einen größeren Rahmen kann z.B. so aussehen: Die vom Modell generierten Daten werden zunächst post-processed: Die LLMs haben keine Map-Funktion, sie können eine Adressangabe wie „Werk Stocken Contitental AG“ [sic] nicht in eine Adresse für die Routenberechnung übersetzen, genausowenig ein Datum wie „nächsten Mittwoch 10 Uhr“ in den „30.03.2022 10:00h“.
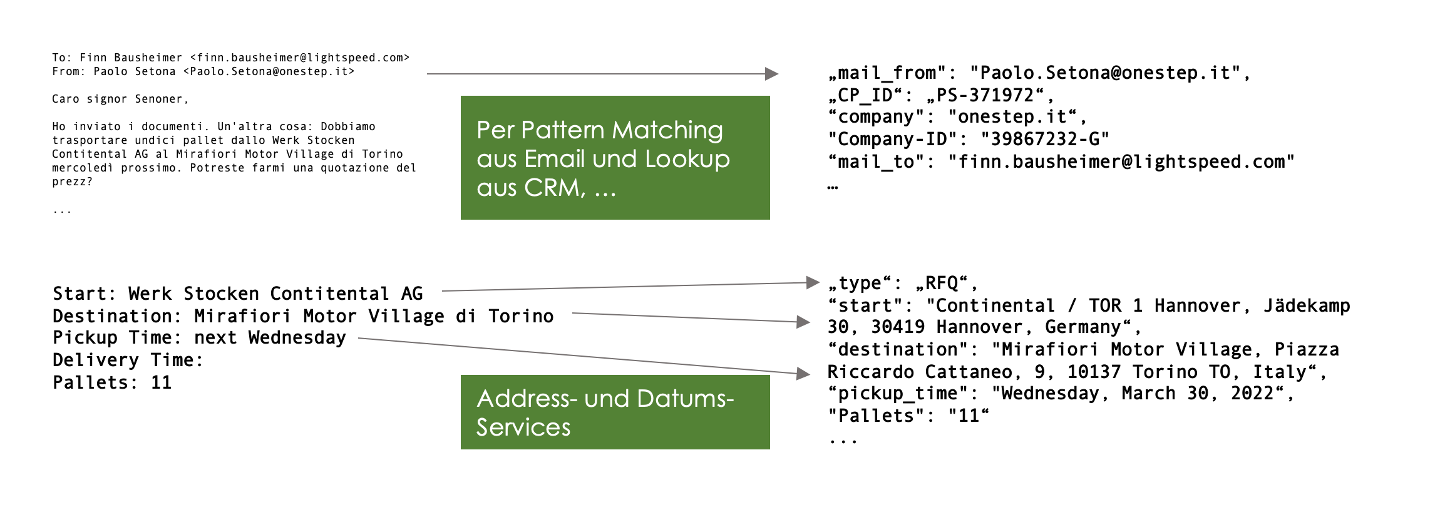
Die prozessierten Daten werden mit den durch einfache Scripts generierten Daten verknüpft und an einen Business Algorithmus übergeben, der die Anfrage automatisiert beantwortet. Nicht automatisch prozessierbare Anfragen werden weiterhin an eine menschliche Person geleitet, die sie manuell bearbeitet. Das kann folgende Fälle umfassen:
- Das Modell erkennt, dass es keine Angebotsanfrage ist.
- Das Modell oder der gescriptete Algorithmus erkennen, dass sie diese Anfrage nicht in Daten umwandeln können.
- Die generierten Daten sind vom Business Algorithmus technisch nicht verarbeitbar.
- Die Anfrage kann trotz vollständig vorliegender Daten nicht automatisiert beantwortet werden, weil z.B. nicht klar ist, ob ein Fulfillment für einen bestimmten Kunden, eine Relation, ein Datum, eine Ladung überhaupt möglich ist bzw. weil gar kein Preis genannt werden kann.
Wenn die generierten Daten automatisiert prozessierbar sind, können sie z.B. einfach in ein System eingespeist werden (z.B. ein Transport Management System) und dort eventuell gleich bearbeitet werden. So kann etwa ein vollständiger Tender per Email auf Basis eines Business Algorithmus generiert werden. Das Charmante an einer solchen Lösung ist, dass ein evtl. fehlerhaftes Verständnis des Modells nicht zu einem inhaltlich in sich falschen Angebot führt, bei dem sich für das Unternehmen Preis- oder Erfüllungsrisiken ergeben. Das Angebot ist vielmehr immer richtig. Im schlimmsten Fall entspricht es lediglich nicht dem genauen Ziel der Anfrage („Wenn ich Neustadt schreibe, ist doch immer Neustadt an der Dosse, nicht an der Weinstraße gemeint“, etc.). Die Lösung kann mit einem Betriebs-Setup, das dem produktiven Zielbild ähnelt, z.B. im Parallelbetrieb getestet werden: Die Mails laufen weiter in die produktiven Systeme, während Clones davon in einem Test-Setup verarbeitet und die Ergebnisse evaluiert werden. Probleme der Verarbeitung sowie des Betriebs-Setup werden hier schnell manifest.
C. Test, Soft Launch und weitere Schritte
Bei Erfolg von Schritt 2 ist es sinnvoll, das System zunächst weich zu launchen, z.B. nur auf eine beschränkte Kundengruppe anzuwenden und dann bei Problemen nachzujustieren. Oder das System am Anfang noch unter menschlicher Supervision laufen zu lassen (Emails werden überprüft, bevor sie rausgehen). Bei Erfolg und Stabilität werden Scope und Automatisierungsgrad dann schrittweise erweitert.
Auch im laufenden Betrieb sollte das System weiter optimiert werden, z.B. indem Anfragen, die nicht richtig erkannt und in die manuelle Bearbeitung geschickt werden, jeweils batchweise nachtrainiert werden.
Je nach Anwendung kann dann ein Automatisierungsgrad von zu Anfang beispielsweise 80% in späteren Phasen auf 90%, 95% erweitert werden.
Die Automatisierung mit Hilfe von LLMs hat drei große Vorteile:
- Möglichkeit, die entsprechenden Teams auf für Menschen spannendere, margenträchtige und wachstumsrelevante Fragestellungen zu setzen
- Massiver Gewinn an Effizienz in der Bearbeitung in Bezug auf die eingesetzte Manpower in Sales, Customer Support, etc.
- Erhöhung der Service-Qualität durch schnellere Antworten und Vermeidung liegengebliebener Anfragen
Im Gegensatz zu händischen Automatisierungsansätzen wie dem Erstellen kundenspezifischer EDI-Verbindungen zahlt eine LLM-basierte Automatisierung auf eine kundenübergreifende Prozessautomatisierung ein. Der Wert des Investments geht nicht durch Wechsel von Schnittstellenspezifikationen oder Änderungen in Kundenbeziehungen verloren. Sie ist auch für den Long-Tail an B2B-Kunden oder gar für B2C Kunden umsetzbar, zu denen man keine spezifische Schnittstelle bauen kann. Eine LLM-basierte Lösung kann und sollte typischerweise mit EDI-Lösungen für Key-Partner kombiniert werden.
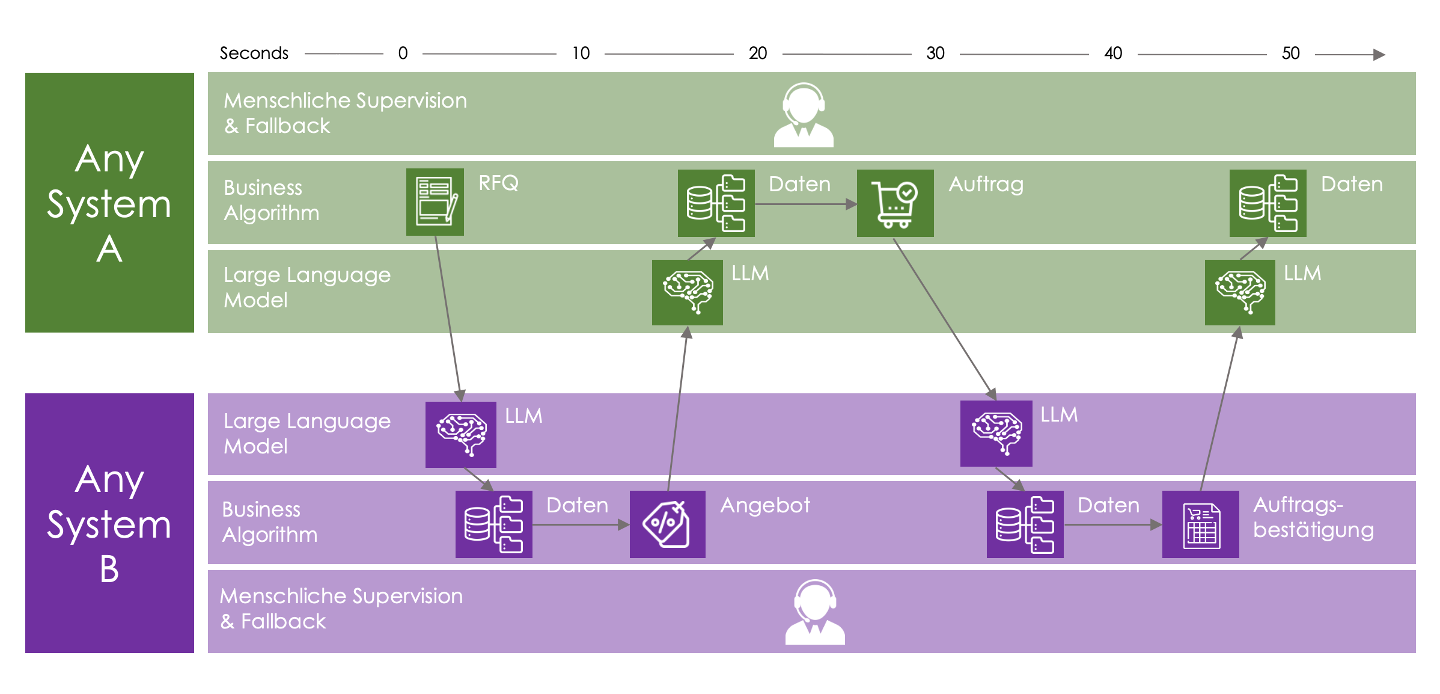
Das langfristige Bild
Wir haben hier ein Szenario skizziert, bei dem menschliche Inputs, ggf. system-generierte (ein RFQ aus einem ERP-System) in ein LLM-unterstütztes System laufen. Die Antwort geht wieder zurück an einen Menschen, der dann beauftragt oder freigibt. Langfristig lässt sich der Ansatz weiter denken: Wenn wir auf beiden Seiten bei Sender und Empfänger ein LLM-unterstütztes System haben, lässt sich der gesamte Abstimmungsprozess weitgehend automatisiert abwickeln, beispielsweise zwischen dem ERP-System eines Auftraggebers und den TMS-Systemen von Auftragnehmern. Das eine System sendet RFQs, die TMS senden Tender, das ERP wählt einen davon aus und schickt eine Beauftragung, das TMS bestätigt und schickt die Beauftragung ins Fulfillment. Eine multidirektionale automatisierte Kommunikation mit beliebigen Partnern wäre damit ohne spezifizierte Schnittstelle einfach und aus dem Stand heraus möglich.
Die Versatilität der LLMs erlaubt es ihnen, mit verschieden formatierten sowie strukturierten Anfragetypen umzugehen — wie ein menschlicher Agent.
Am Anfang wäre der mögliche Scope und die Qualität der Bearbeitung sicherlich nur auf dem Niveau eines 1st Level Supports möglich. Komplexere oder unbeantwortbare Anfragen müssen zuverlässig erkannt und dann zu einem menschlichen 2nd Level Processing weiter geleitet werden.
Dennoch wären massive Zeitersparnis und Prozessbeschleunigung die positiven Effekte. Zudem können die Systeme sich automatisch oder halbautomatisch durch das Training mit eben den Anfragen, die sie noch nicht/ noch nicht zuverlässig beantworten können, verbessern.
Und die Menschen im Office? Sie können sich endlich auf höherwertige Aufgaben konzentrieren, als die Inhalte von Emails oder PDFs in ein Formular zu kopieren, ein paar Knöpfe zu drücken und die Ausgabe wieder in eine weitere Email zu packen.
Titelbild: @floschmaezz on unsplash, bearbeitet.
Danke für Inspirationen, Support, Feedback an: Alexander Polzin, Almudena Pereira, Hoa Le van Lessen, Jochen Emig, Kirsten Küppers, Mathias Sinn, Max Heintze
Natürlich bin ich für den Inhalt des Beitrags selbst verantwortlich.