In den letzten Monaten, sind vielversprechende Language Models auf dem Markt gekommen. Ich habe einige dieser Plattformen getestet und mit Daten beworfen. Können andere Modelle GPT-3 das Wasser reichen? Oder sind sie sogar besser?
Alle Plattformen bringen spezielle Eigenschaften mit, die sich teilweise nur schwer vergleichen lassen: Wie etwa die Fähigkeit, Programm-Code zu generieren und zu verstehen, der SQL-ähnliche Tabellenverarbeitung, oder bestimmte Sprachen abzudecken. Um einen fairen Vergleich anzustellen, habe ich einige grundlegende Tests im Bereich Weltwissen durchgeführt, sowie die Fähigkeit logische Schlüsse zu ziehen. Testsprache war Englisch.
Kurze Intro der Plattformen:
Muse ist ein Sprachmodell des Startups LightOn aus Paris, das ein Funding von knapp 4 Mio. $ erhalten hat. Fokus liegt auf europäischen Sprachen.

Aleph Alpha ist ein Startup aus Heidelberg und hat knapp 30 Mio. $ von VCs eingesammelt. Neben seinem sehr guten, rein sprachlichem Interface besitzt es die Fähigkeit, multimodalen Input zu verarbeiten.

AI21 Labs ist ein Startup aus Tel Aviv. Insgesamt hat das Unternehmen 118 Mio. $ eingesammelt. Eines der ersten GPT-3 Konkurrenzmodelle.

GPT-3 von OpenAI in San Francisco ist das LLM, das in den letzten Jahren wahrscheinlich am meisten Furore gemacht hat und eine Art Gold Standart für Sprachmodelle ist.
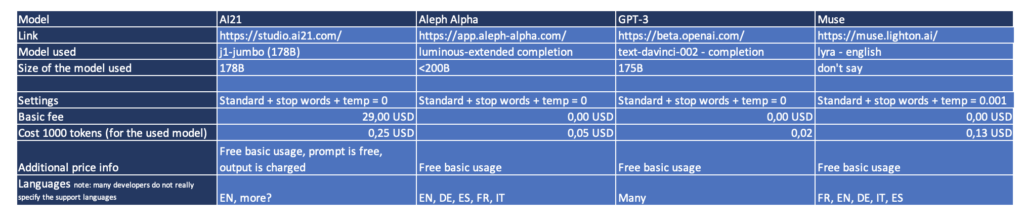
Hier ein Überblick über die Teilnehmer inkl. spezifische Modelle und Test-Settings.
Aber: Was ist ein Large Language Model überhaupt?
Large Language Models sind Automaten, die meist eine spezifische Architektur aufweisen (Transformer) und mit Gigabyte und Terabyte von Texten aus dem Internet (z.B Wikipedia) trainiert worden sind. Auf Basis dieser Daten leiten sie die Wahrscheinlichkeiten von Wortsequenzen ab. Im Prinzip können sie diese Automaten prognostizieren, wie eine Folge von Wörtern, ein Satz, eine Geschichte, eine Unterhaltung weitergeht. Und das nur auf Basis ihres gigantischen Lerndatensatzes.
Der Test: Weltwissen und einfache Logik
Ich lasse verschiedene Large Language Models gegeneinander antreten, indem ich ihr Weltwissen und ihre Fähigkeit zu Schlussfolgern prüfe. Modelle, die ihn bestehen, können für eine Vielzahl von Einzelanwendungen eingesetzt werden: z.B. für die Beantwortung von Kundenfragen, für die Analyse und Zusammenfassung von Texten und die automatische Bearbeitung von Mails. Dieser Test ist spezifisch für Large Language Models konzipiert: Klassische regelbasierte Sprachsysteme wie Alexa steigen ab einer bestimmten Komplexität der Fragen aus und können diese nicht mehr beantworten. Ich habe Alexa, als das am weitesten entwickelte klassische Sprachmodell dieselben Fragen gestellt, um die Fähigkeiten der verschiedenerer Plattform-Architekturen zu vergleichen.
1) Fakten
Diese Fragen haben jeweils eine exakt richtige Antwort. Jedes Modell sollte in der Lage sein, diese Fragen zu beantworten.

- Die ersten drei Modelle beantworten die Frage richtig
- Der Hinweis von GPT-3 auf die Schwerkraft führt hier zu einem Extra-Sternchen
- Muse, really, „North?“
- Alexa googelt nach einer Antwort und entgegnet mit etwas komplett falschem.
2) Weiches Wissen / vernünftige Einschätzungen
Die Antworten auf die folgenden Fragen sind nicht mit reinem Faktenwissen zu beantworten. Hier muss eine Schlussfolgerung gezogen oder eine Einschätzung gegeben werden. Unterschiedliche Antworten sind möglich, mehrere können richtig sein.

- Drei Modelle haben die Frage halbwegs richtig beantwortet. Ja, im Prinzip könnte man die Pedale und den Sitz eines Fahrrads abschrauben, aber das verlangt Akrobatik – deswegen nur 3 von 5 Sternen.
- Alexa liefert eine Antwort aus einem Fahrradforum, das sich mit der Frage beschäftigt, wie sich ein Quietschen beheben lässt. Das ist Nonsense.
- Der Muse-Vorschlag, das Vorderrad während der Fahrt zu entfernen, ist mir zu gefährlich: nur ein Punkt.
- Liebe Modelle, warum nicht einfach die Klingel?
3) Harte Nüsse mit logischem Schlussfolgern und Kontextverständnis:
Jetzt wird es sehr, sehr schwer. Ich stelle Fragen, die auch Menschen nicht leicht beantworten können.

Eine richtige Antwort auf die erste Frage wäre, dass es dazu keine genauen Daten gibt oder dass es wahrscheinlich ungefähr genauso viele sind.
- AI21 liegt bei der zweiten Aussage im Prinzip richtig (es gibt tatsächlich mehr Männer), das ist aber kein logischer Grund für die erste Aussage.
- Auch GPT-3 bekommt von mir nicht die volle Punktzahl. Hier fehlt eine Einschätzung oder der Verweis auf fehlende öffentlich verfügbare Informationen.
- Alexas Antwort von 6,6% ist ziemlich sicher falsch, geht aber immerhin in die richtige Richtung.
- Die Modelle beantworten die Frage alle außer GPT-3 instinktiv falsch und schieben teilweise fragwürdige Erklärungen hinterher.
Final countdown – Wie schlagen sich die new beasts unter den Transformern gegenüber GPT-3?
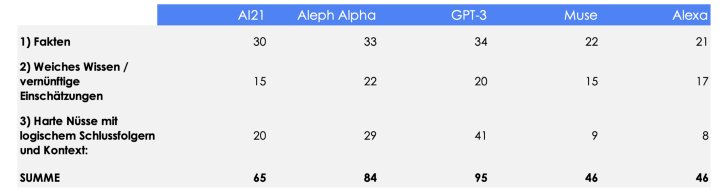
Das Ergebnis meines subjektiven Tests war für mich teilweise sehr unerwartet:
- ALLE Modelle außer Muse sind im Feld Weltwissen / logische Schlussfolgerungen besser als Alexa. Das bedeutet nicht, dass Alexa doof ist. Immerhin stellt sie das elaborierteste sprachbasierte Assistenzsystem dar. Sie kann viele Dinge, wie die Uhrzeit nennen, Musik abspielen, einen Timer setzen, eine Verkehrsauskunft geben und tausend weitere Aufgaben, die die LLM – Modelle nicht mal ansatzweise beherrschen. Sie kann aber praktisch nichts, wofür sie nicht explizit programmiert wurde.
- GPT-3 führt immer noch unter den LLMs. GPT-3 schließt nicht nur ingesamt besser ab als alle anderen Modelle, sondern knackt mit Bravour auch die härteste logische Nuss im Test.
- AI21 und vor allem Aleph Alpha sind GPT-3 auf den Fersen. Gerade Aleph Alpha leistet auch im Hinblick des überschaubaren Fundings eine Menge und hat in dem Test nur wenige gravierende Schnitzer gemacht. Beiden Modellen traue ich zu, dass sie in den nächsten Monaten weiter zu GPT-3 aufschließen. Das hoffe ich auch für alle Anwender, die damit deutlich mehr Auswahl gewinnen.
Vielen Dank an: Kirsten Küppers, Hoa Le van Lessen und Almudena Pereira für Inspiration und Support bei diesem Beitrag!
Stay tuned: Meine nächsten Tests drehen sich um die Frage, wie die Modelle im Kontext von Business Fragestellungen abschneiden.
Lesen Sie den vollständigen Artikel auf medium.com/@maximilianvogel.