What if every email, every PDF with an order, an invoice, a complaint, a request for an offer or a job application could be translated into machine-readable data? And could then be automatically processed by the ERP / CRM / LMS / TMS …? Without programming a special interface.
Sounds magic? It does have some magic to it. But has been made possible recently.
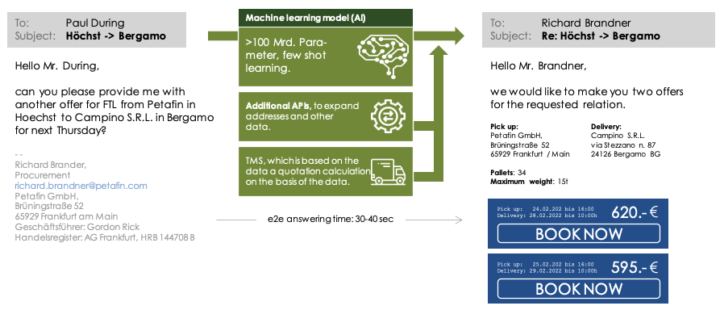
The solution are Large Language Models (LLMs). These are – similar to a human office worker – able to convert an email into structured data with no or only few learning samples. The email, PDF or document is recognized as an order, a tender, a reminder. And the specific data is found and extracted. For example, for a transport order request, the client, number of pallets, weight, pickup location, pickup time, delivery location.
An additional business algorithm (- this is not done by the model) can then either pre-filter the query based on the structured data, process it directly (e.g. answer it) or provide it to a human agent as structured input, possibly also with a suggestion for further processing.
What are Large Language Models and why should we care?
The development of large language models has been a major milestone in machine learning in recent years. The special feature of the models is their ability to answer questions in natural language, to create texts, to summarize them, to translate them into other languages or language games, or to produce code – and all this without scripting, i.e. without a specially programmed algorithm that links user inputs with machine outputs. The models not only produce syntactically (orthographically, grammatically) correct output, but are also able to solve difficult linguistic tasks semantically correctly. There are a number of LLMs – the most prominent include GPT-3 (OpenAI), BERT, T5 (Google) or Wu Dao (Beijing Academy of Artificial Intelligence), MT-NLG (Microsoft).
LLMs show amazing skills in answering questions, and continuing or summarizing text. In many cases, their skills even surpass those of a human communication partner. Here are some examples of the abilities of three LLMs: GPT-3 davinci, AI21 studio j1-jumbo, Macaw 11B. None of the tasks were specifically trained, and no response is scripted. Rather, these are examples of zero shot competence: the ability to do something without having specifically trained it.

Structured data can also be generated, e.g. simple programs:

The models are typically able to process other widely spoken languages as well, though none as well as English.

Some of the models can analyze and summarize larger text / input sets.

How do LLMS work?
The LLMs answered all the questions correctly (- except for the one about the best Star Wars episode). How is this possible?
A quick glimpse on the basics of Large Language Models: the most powerful systems are Transformer Models, which at their core consist of a Deep Learning Model (a specific type of neural network) and are equipped with an Attention Mechanism. They are able to process sequential input (e.g. text) and produce corresponding output. They do this essentially on the basis of statistics: What is the most probable continuation (answer to a question, next utterance in a dialog, completion of a started text)? – That means, their responses are not based on a fixed mapping of user intents to answers as Siri, Alexa, or other voice assistants currently are.
The models are Large in every dimension: they now typically consist of more than 100 billion parameters. Parameters, simply put, are the weights between neurons that are adjusted as the model learns. The models were trained with several hundred gigabyte of mostly publicly available data such as Wikipedia and similar large corpora. The training content is equivalent in size to that of well over a hundred thousand books. To put this into perspective: It is difficult for a human to read more than 5,000 books in a lifetime. The ecological footprint of these models is also enormous: According to estimates, the initial training of the most successful LLM cost as much energy as it takes to drive a car to the moon and back. Quantity translates into quality to some extent for LLMs. The current achievements have been made possible through the tenfold, hundredfold, and thousandfold increase of the size of the models over the past 2-3 years.
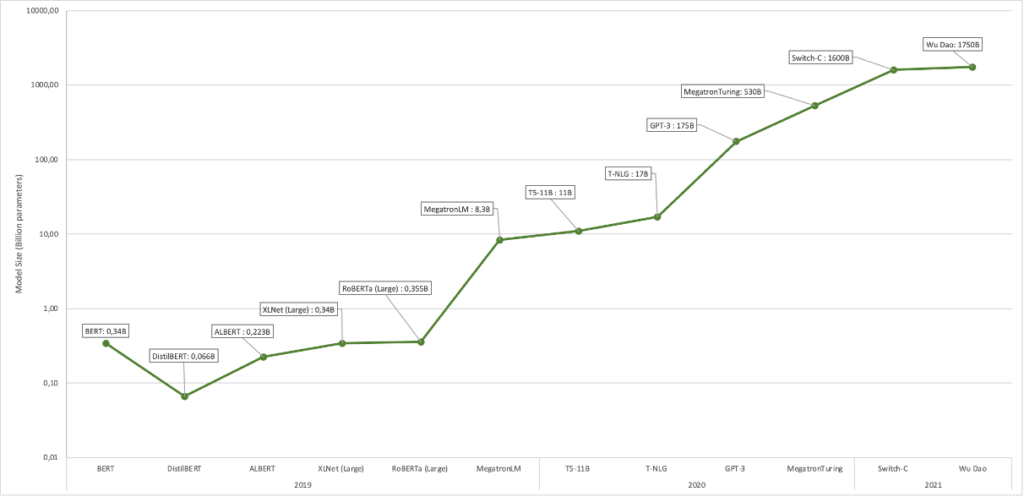
A feature of the newer LLMs is that – as in the examples shown above – they can provide responses to inputs without task-specific learning. Their output relies only on their basic training. Similar to humans, these models are versatile and able to understand and correctly converse or respond to a new language game taught on single-shot training (a single practice example), few-shot training (a few examples), or even on no examples at all. This is new and revolutionary. Earlier models were painstakingly trained to do exactly one job and could only handle that single task: playing chess, identifying suspicious banking activity, finding faces in pictures, etc.
Of course, some fine-tuning is possible here as well, i.e. training the models for a specific job with additional sample inputs and outputs. This, too, is similar to human language acquisition: after about 20 years of basic training in childhood and adolescence, we can chat, argue, philosophize, lie, calculate, spin around, analyze or preach. But in order to do this at a high and specific professional level, we study law, quantum physics, accounting, psychology or theology.
Limitations of the LLMs
The models’ abilities are limited: they fail in arithmetic skills concerning numbers beyond the multiplication table. Often they seem to simply only guess. Unlike answering questions or completing texts, difficult mathematical tasks cannot be solved – as the models do – by statistics and on the basis of enormous amounts of training data. Asked tricky questions the models make similar careless mistakes as humans do. Their knowledge of the world remains at the level of their last training point, e.g. at the end of 2019 with GPT-3. In addition, they are unable to assess whether they are really well versed in many technical fields and able to answer correctly. Above all, this deficit makes it necessary to monitor the models.

An interesting area in which the models do score is the analysis of texts. In the following example, we tell the model what to do and give two examples: iPhone and Serrano ham. For the third input (cider), the model itself manages to provide the correct answer (few shot learning).

Also more structured data can be analyzed. The following example (again based on few shot learning) shows a kind of database query without database and SQL, but simply is based on linguistic skills. Similar to what a human would be able to do.

An Automation Setup with Large Language Models
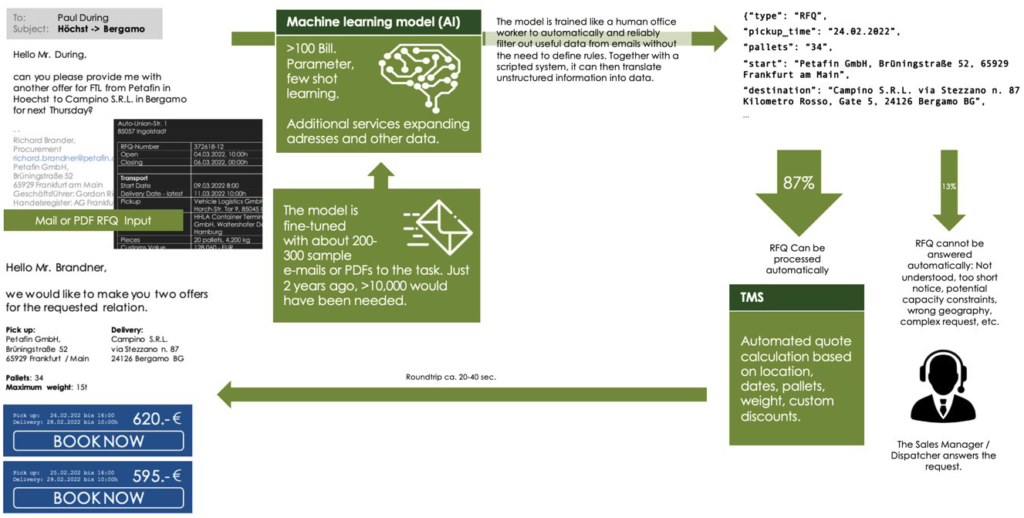
How can language models be used to convert unstructured data into structured data and process it automatically? An implementation example from our own practical experience will demonstrate this. (- Of course, we are definitely not the only ones dealing with these matters, see also this paper).
A. Setup of the model (POC 1)
Question: We receive unstructured mails, possibly in different languages, as an offer request for a transport and try to convert them into structured data.
In order to do this, we provide the model with some training samples (-a few dozen to a few hundred samples). The samples should be as diverse as possible so the model learns to deal with the full range of requests. The samples should also cover intents other than just RFQs: e.g., inquiries regarding a shipment in progress or complaints in order to help the model distinguish the correct classification. Training samples include the payload of an email or PDF text as well as structured data to be output. Any data that can be drawn from the email via simple scripting and does not require machine learning should be removed in advance, such as the sender address or the recipient address. The input should contain real data, not manually cleaned, but with spelling errors, colloquial time and all possible languages. The target data does not have to be in a standalone format (JSON, etc.) in order to start. The conversion can again be accomplished via simple algorithms.
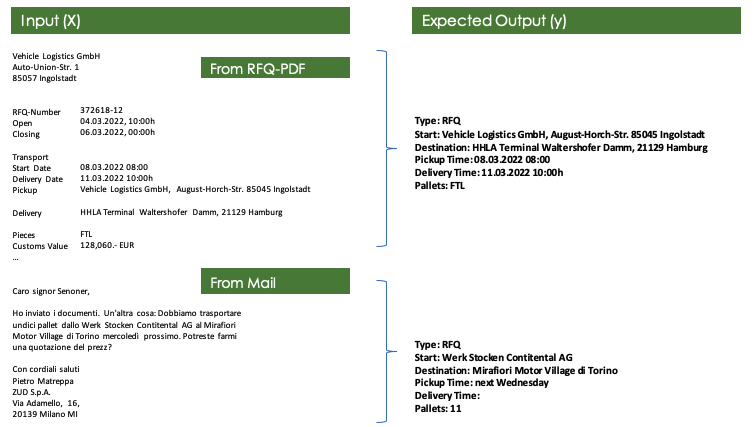
The data is used to tune a model that can then be used to recognize and process any number of other queries..
Which base model should you use for your application? This question is not easily answered, rather it should be broken down into several sub-questions:
- Which model in which configuration, with which settings offers the best results?
- Which model can I operate in my desired setup (operation in own cloud, SaaS solution, etc.) and with my requirements (e.g. privacy, data sovereignty)?
- Which model has the lowest total cost of ownership (fixed and request-based costs)?
If several models from the perspective of questions 2 and 3 are in the relevant set, these should be tested with different settings. In order to find the optimal solution, you should test the model on the basis of first some training and few test data, then succeed with more. The scope of the machine processing can also still change, certain query categories or certain data are possibly integrated or removed after the evaluation of the first results.
If this is successful and you achieve a sufficiently high rate of correct answers for the business purpose, the next step can be taken. Which rate is sufficient can vary depending on the application, it can be 60%, 80% or 98%. It is important to separate training and test data during the trial in order to achieve results that can be reproduced in later production operation.
B. Integration into an overall E2E solution (POC 2)
The integration into a larger framework can look like this: The data generated by the model is first post-processed: The LLMs do not have a map function, they cannot translate an address information like “Werk Stocken Contitental AG” [sic] into an address for a route calculation, just as they cannot translate a date like “next Wednesday 10am” into “30.03.2022 10:00h”.
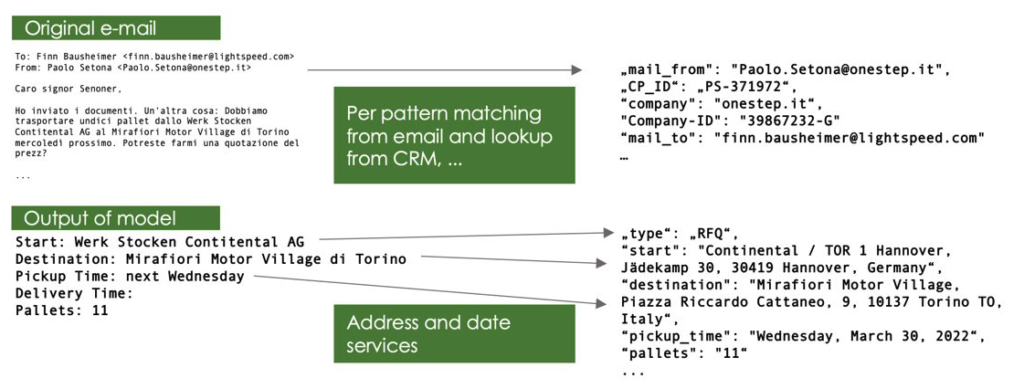
The processed data is linked to the data generated by simple scripts and passed to a business algorithm that automatically answers the query. Requests that cannot be processed automatically are still routed to a human person who processes them manually. This can include the following cases:
- The model recognizes that this is not a request for proposal.
- The model or scripted algorithm recognizes that they cannot convert this request into data.
- The generated data is technically unprocessable by the business algorithm.
- The request cannot be answered automatically despite a complete data set being available because, for example, it is not clear whether fulfillment is even possible for a particular customer, relation, date, or load, or because no price can be proposed at all.
If the generated data can be processed automatically, it can, for example, simply be fed into a system (e.g. a transport management system) and can possibly be processed there immediately. For example, a complete tender could be generated by email – simply based on a business algorithm. What is charming about such a solution is that a possible misunderstanding of the model does not lead to an offer that is inherently wrong in terms of content, with price or fulfillment risks for the company. On the contrary, the offer is always correct. In the worst case, it merely does not correspond to the exact target of the request (“When I write Paris, it is always Paris, TX, not Paris, France”, etc.). The solution can be tested with an operating setup similar to the productive target image, e.g. in parallel operation: Mails continue to run into the productive systems while clones of them are processed in a test setup and the results are evaluated. Problems with the processing as well as the operational setup here quickly become manifest.
C. Test, soft launch and further steps
If step 2 is successful, it makes sense to soft-launch the system first, e.g., apply it only to a limited group of customers, and then readjust if problems arise. Or let the system run under human supervision at the beginning (emails are checked before they are sent). If the system is successful and stable, the scope and degree of automation can then be gradually expanded.
The system should also be further optimized during operation, e.g. by retraining requests that are not recognized correctly and sent for manual processing.
Depending on the application, a degree of automation of, for example, 80% at the beginning can then be extended to 90% or 95% in later phases.
Automation using LLMs has three major advantages:
- Ability to put the appropriate teams on more exciting, high-margin and growth-relevant issues for humans
- Massive gain in processing efficiency in terms of deployed manpower in Sales, Customer Support, etc.
- Increase in service quality due to faster responses and avoidance of stalled inquiries
Unlike manual automation approaches such as creating customer-specific EDI connections, LLM-based automation pays for cross-customer process automation. The value of the investment is not lost due to changes in interface specifications or changes in customer relationships. It can also be implemented for the long tail of B2B customers or even B2C customers to whom you cannot build a specific interface. An LLM-based solution can and should typically be combined with EDI solutions for key partners.
The long term picture
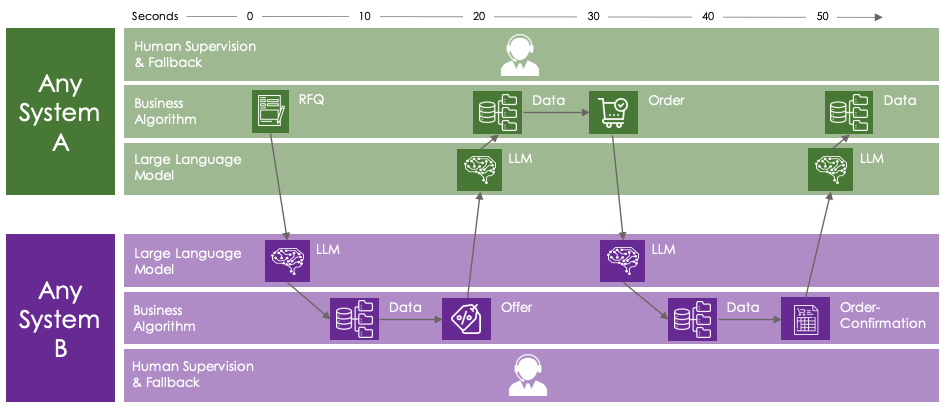
We have outlined a scenario where human inputs, possibly system-generated (an RFQ from an ERP system) run into an LLM-supported system. The response heads back to a human, who then commissions or releases. In the long run, we can imagine further scenarios: if we have an LLM-supported system on both the sender and receiver end, the entire reconciliation process could be largely automated, for example, between a client’s ERP system and contractors’ TMS systems. One system sends RFQs, the TMSs send tenders, the ERP selects one of these and sends an order, the TMS confirms and sends the order to fulfillment. Multi-directional automated communication with any partner would thus be easy and viable without a specified interface.
The versatility of LLMs allows them to deal with differently formatted as well as structured request types – just like a human agent.
Initially, the possible scope and quality of dealing with requests would certainly only be possible at the level of 1st level support. More complex or unanswerable requests would need to be reliably identified and then routed to human 2nd level processing.
Nevertheless, massive time savings and process acceleration would be the positive effects. In addition, the systems can improve automatically or semi-automatically through training with the very queries that they cannot yet/not yet reliably answer.
And the people in the office? They can finally focus on more challenging tasks than copying the contents of emails or PDFs into a form, pressing a few buttons, and copying the output into another email.
Title image: @floschmaezz on unsplash, edited.
Thanks for inspiration, support, feedback to: Alexander Polzin, Almudena Pereira, Hoa Le van Lessen, Jochen Emig, Kirsten Küppers, Mathias Sinn, Max Heintze
Of course, I am responsible for the content of the post.