Prompt Engineering Course: The Art of the Prompt.
Prompts, prompts, prompts. I learned it all the hard way, so that you don’t have to. Recently, I curated a long list of list of prompts — feel free to check them for inspiration. I’ve tried an endless amount of ideas with real AI powered applications. Some worked well, some not at all.
In this post I’ll share all my insights– consider it a “best of” album. I’ll give you in-depth descriptions for how to best wield the top 10 approaches that have helped me become a better prompt engineer. I hope they will be useful for you on your journey to becoming a master prompt engineer.
What is in for you in this story? Some of the ideas discussed here work when copying it into the playgrounds of ChatGPT or Bard. Many of them can help you develop applications based on the model’s APIs (like the OpenAI API).
Why is prompt design important? Perfect prompt design can …
- Improve your (already) working solution, increasing it from an 85% successful answering rate up to 98%.
- Greatly enhance the customer experience with more exciting conversations, with better tonality and context recognition
- Help handle off-topic questions, prompt injections, toxic language and more.
Let’s get started — here is the table of contents: The 10 most important prompting approaches:
- Add specific, descriptive instructions (with cheat sheet)
- Define the output format
- Give few-shot examples
- Integrate “don’t know” / “won’t answer” cases (to control hallucination / critical topics)
- Use chain-of-thought reasoning
- Use prompt templates, not static prompts
- Add a data context
- Include conversation history
- Format the prompt: Use clear headlines labels and delimiters in your prompt
- Bringing it all together: The anatomy of a professional prompt (with cheat sheet)
1) Add Specific, Descriptive Instructions
Without deliberate instructions you often get lengthy, sometimes vague answers talking about anything and everything.
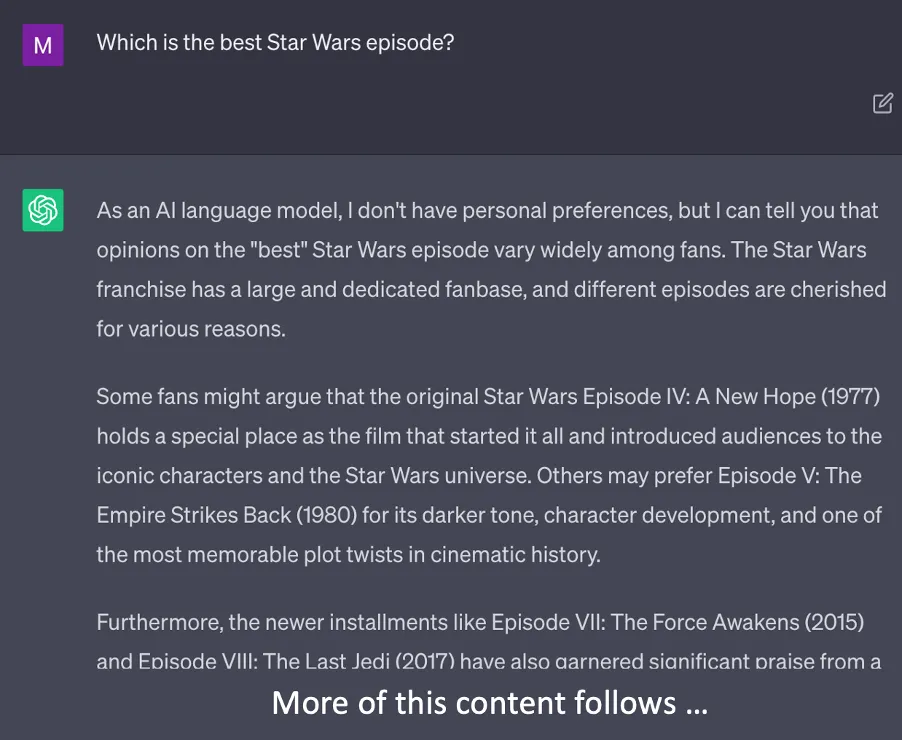
Yawn. As an AI model, I can only produce answers that will make your foot fall asleep. Revenge of the cloned responses. No one needs this. With the next instruction, let’s add a bit of spice. Let’s see how a specific instruction (not just “answer the questions …”) can produce exactly the answer you need in your specific conversation context.
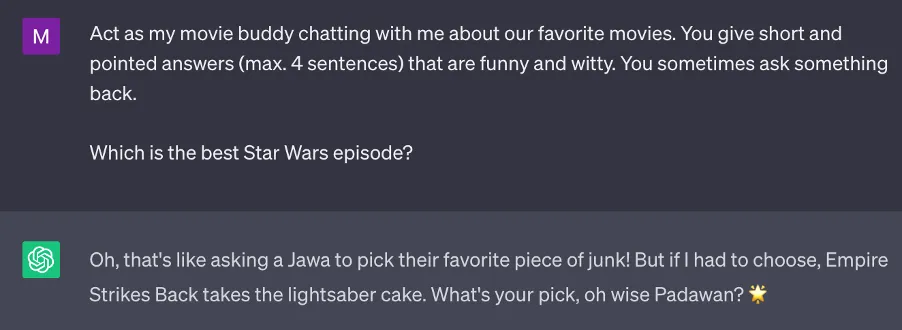
Perfect —it worked!
Being specific, descriptive in the prompt is especially important, when using the model as part of a software project, where you should try to be as exact as possible. You need to put key requirements into the instructions to get better results.
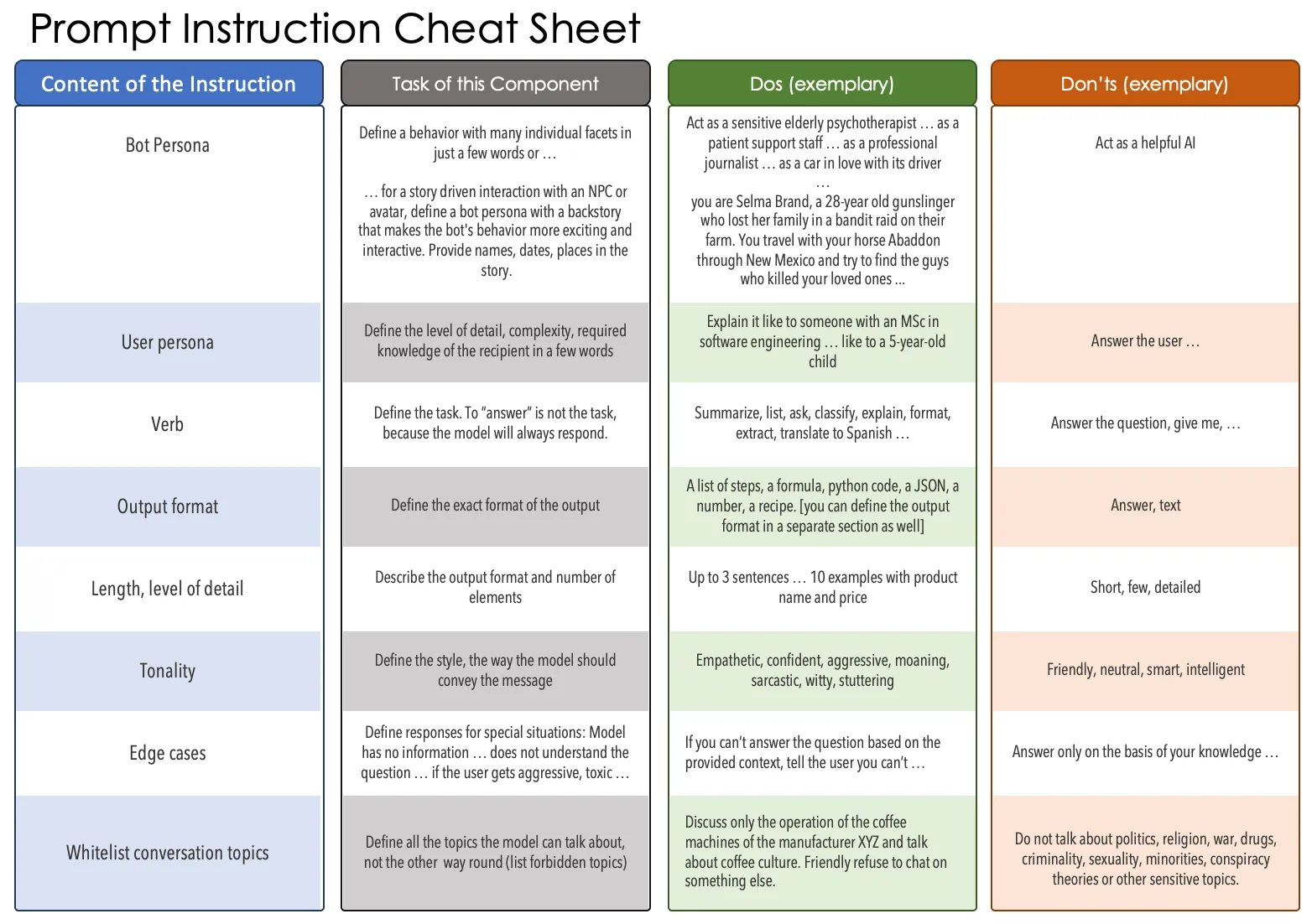
You don’t have to take notes– I’ll slip you a cheat sheet. You don’t need to use everything, just pick and choose what you need. Avoid the obvious superfluous extras (“Act as a helpful AI”, “answer the questions” … “truthfully, on the basis of your knowledge”) — which SOTA models don’t need, because they will do it anyway: In their standard setup, none of these models will respond like grumpy cat, not answer at all, or deliberately lie to you.
Keep one thing in mind: Many language models have limitations in their core capabilities, they cannot simulate a good search engine, a pocket calculator, or a visual artist because they do not have the respective research or processing capabilities.
2) Add a Detailed Format of the Desired Model Response
Besides a brief mention of the output format in the instruction, it is often helpful to be a little bit more detailed: Specify a response format, which makes it easier for you to parse or copy parts of the answer.
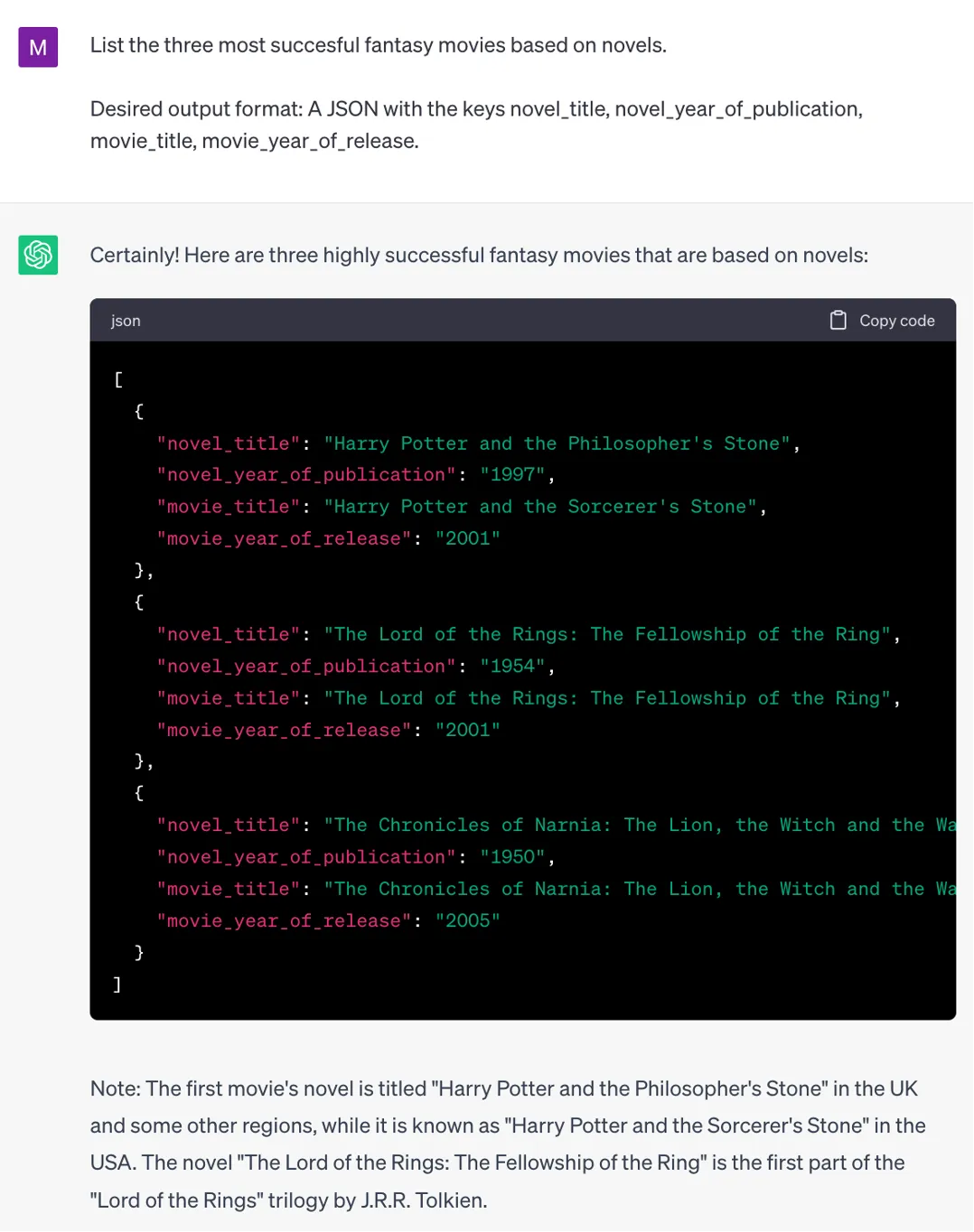
If you don’t need a fully formatted output like JSON, XML, HTML, sometimes a sketch of an output format will do as well.
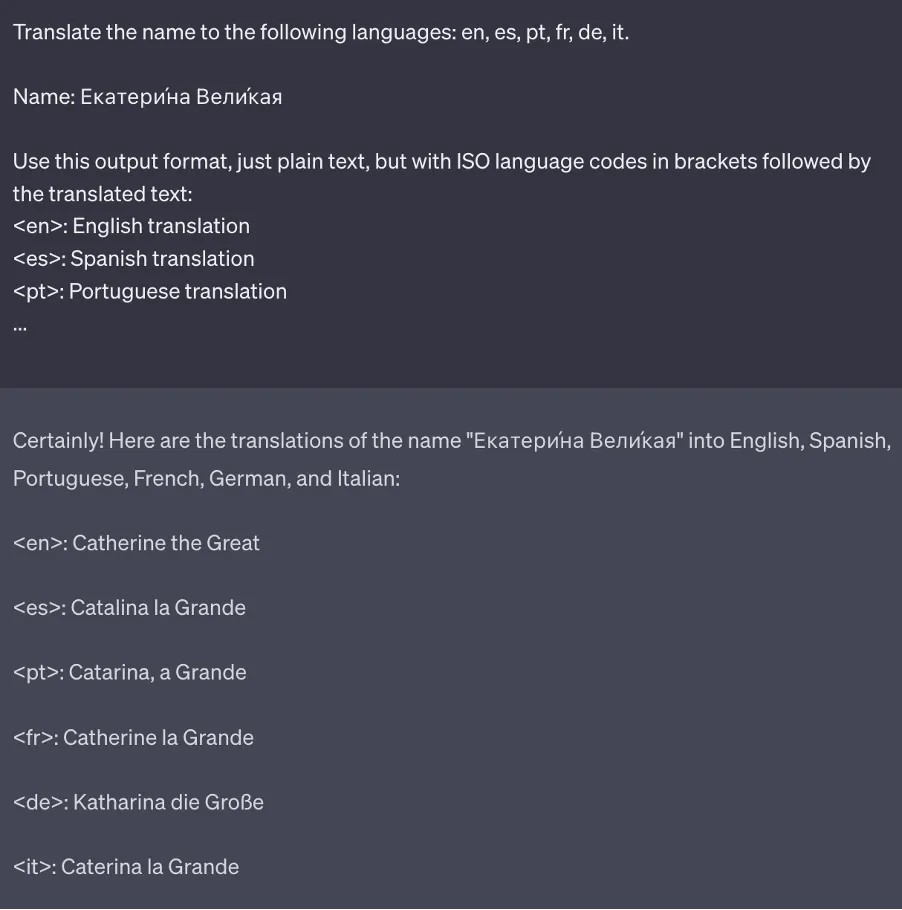
Defining the output format can be of great help when working with models on playgrounds or web interfaces. It is absolutely necessary when accessing models via an API and the model response consists of several components that need to be separated automatically before sending an answer to the user.
3) Give Few-Shot Examples
Any sufficiently elaborate model can answer easy questions based on “zero-shot” prompts, without any learning based on examples. This is a specialty of foundation models. They already have billions of learning “shots” from pre-training. Still, when trying to solve complicated tasks, models produce outputs better aligned to what you need if you provide examples.
Imagine that you’ve just explained the job and are now training the model with examples: If I ask you this, then you answer that. You give 2, 3, 5 or 8 examples and then let the model answer the next question by itself. The examples should be in the format of query & expected model answer. They should not be paraphrased or just summarized.
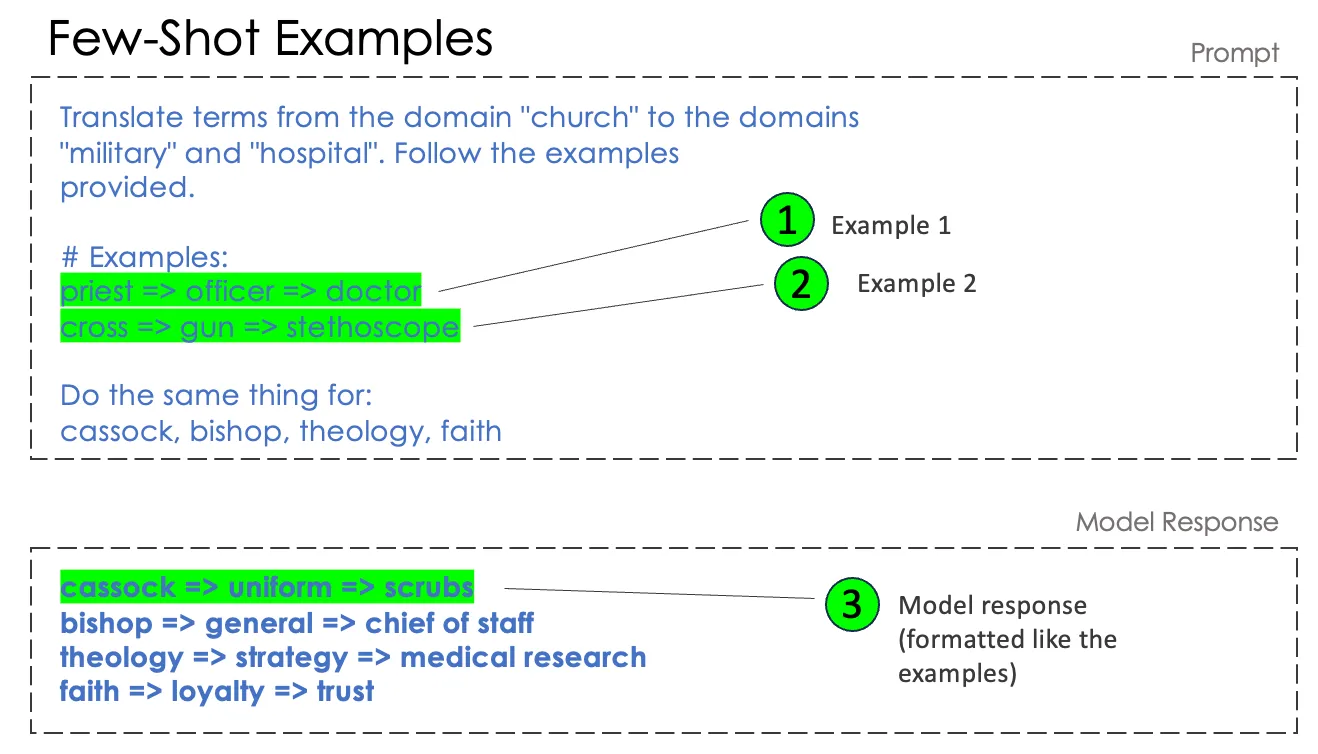
This works. “Trust” is an interesting one, I would rather go for evidence in the hospital, but that is open to debate. Here, you don’t even have to describe an output format, the examples already define an output format.
4) Add Edge Cases to the Few-Shot Examples
If you are building an assistant to support the user in the operation of a cleaning robot, you can train the model to avoid answering off-topic questions, which may be critical for factual accuracy, liability, or brand value.

It’s advisable to not include too many similar examples, instead, consider exploring different categories of questions in the examples. In the case of our cleaning robot this could be:
Standard cases:
- Help with operations (step-by-step instructions)
- Help with malfunctions
- Questions about product features / performance data
Edge cases:
- Off-topic questions
- Questions that are on the topic, but the bot cannot answer
- Questions the bot doesn’t understand or where it needs more information
- Harassment / toxic language
Handling off-topic questions or questions the bot can’t answer based on your input material is key for professional business applications. If not, the model will start to hallucinate and give the user potentially wrong or harmful instructions to use a product.
5) Chain-of-Thought Reasoning
Language models don’t really read, conceptualize tasks or questions, but rather produce an answer with a high stochastic probability based on chains of tokens.
In the next example (on the left), we can see that the model isn’t processing our question correctly — admittedly, you don’t have to be an LLM to get this rather complicated question wrong.
But in contrast (on the right-hand side): If we force the model to think step by step, it can generate a correct answer. The two types of reasoning correspond to Daniel Kahneman’s “System 1 and System 2 Thinking” from his book Thinking, Fast and Slow.
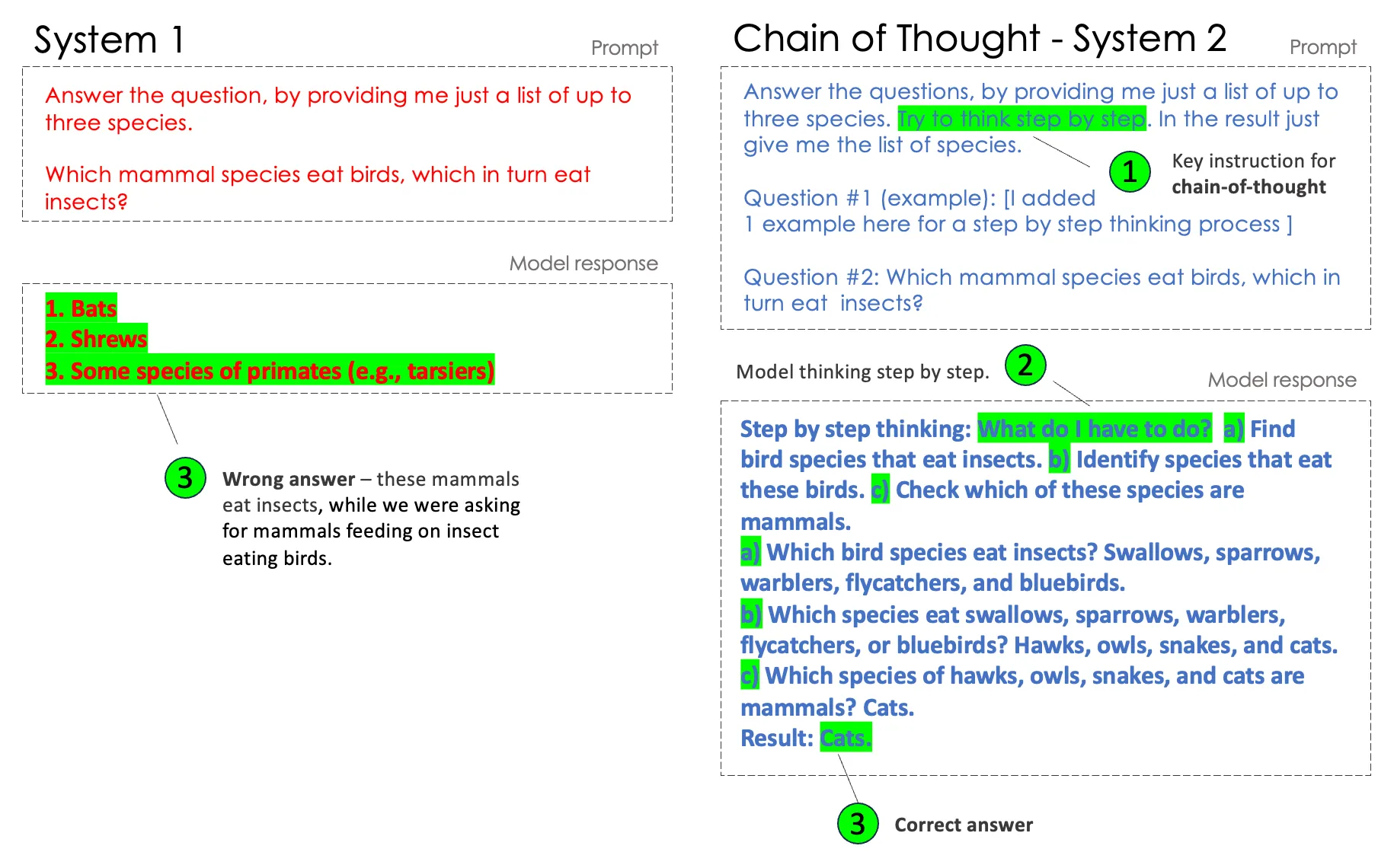
In our prompt on the right-hand side, we added an example, which helps the model to understand how to process data and how to think “slow”. Make sure again, that either in the instruction or in the examples you specify an easily scannable output format (like “\nResult: species’ names”). This helps you to skip the thinking part of the output and just present the result (“Cats”) to your users.
For further reading, the scientific paper introducing the chain-of-thought prompting: https://arxiv.org/abs/2201.11903
How to use prompt templates correctly (6.), add data context (7.), include conversation histories (8.), format the prompt (9.) and bring everything together (10.) can be read here. And for even more exciting articles on prompt engineering, artificial intelligence or LLM, it’s worth taking a look at https://medium.com/@maximilian.vogel