In the last few month, some promising language models went live challenging GPT-3. I tested a few like these platforms and threw data at them. Always with questions in mind like: Can other models compete with GPT-3? Or are they even better?
All platforms bring special features that are sometimes difficult to compare: For example, the ability to generate and understand program code, SQL- like table processing, or to cover specific languages – the Muse language model is very strong in French, for example. To make a fair comparison, I did some basic tests in the area of general knowledge, as well as the ability to draw logical conclusions. The testing language was Englisch.
Short intro of the platforms:
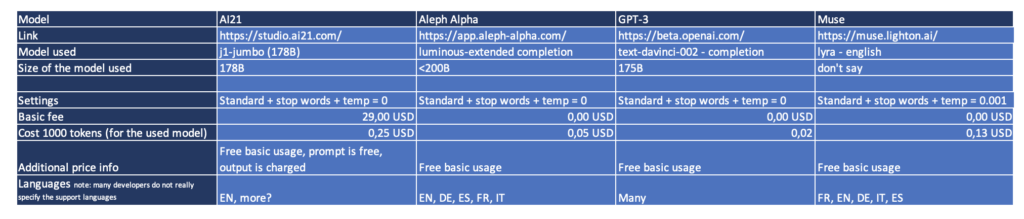
Muse is a language model from Paris-based startup LightOn, which has received funding of about close to $4 million. Muse has a focus on European languages.

Aleph Alpha is a startup from Heidelberg in Germany. Aleph Alpha has raised almost $30 million from VCs. In addition to a very good pure speech interface, Aleph Alpha has the ability to process multimodal input.

AI21 Labs is a Tel Aviv- based startup and last received funding in July 2022. In total, the company raised $118 million. The platform developed by AI21 was one of the first GPT-3 competitor models.

GPT-3 from OpenAi in San Francisco is the LLMs that has probably made the biggest splash in recent years and is a kind of gold standard for language models.
Here is an overview of the participants in the small competition including specific models and test settings.
But was is a large language model anyway?
Large Language Models are systems that usually have a specific architecture (transformer) and have been trained with gigabytes and terabytes of texts from the internet (e.g. Wikipedia). Based on this data, they derive the probabilities of word sequences. In principle, these machines can predict how a sequence of words, a sentence, a story, a conversation will continue. And that’s just based on their gigantic learning data set.
The test: general knowledge and simple reasoning
I have the models compete agains each other by testing their knowledge of the world and their ability to reason. Models that pass it can be used for a variety of individual applications: e.g., answering customer questions, analyzing and summarizing texts, and automatically processing mails. This test is specifically designed for Large Language Models: Classical rule-based language systems like Alexa drop out after a certain complexity of questions and can no longer answer them. I asked Alexa, as the most advanced classical language model, the same questions in order to compare the capabilities of different platform architectures.
1) Facts
These questions each have one or more exactly correct answers. Each model should be able to answer these questions.

- The first three models answer the questions correctly.
- GPT-3’s reference to gravity deserves an extra gold star.
- Muse, really, “North?”
- Alexa googles for an answer and responds with something completely wrong.
2) Soft knowledge / reasonable assessments
The answers to the following questions cannot be answered with pure factual knowledge. A conclusion must be drawn or an assessment must be made here. Different answers are possible, several can be correct to some extent.

- Three models answered the questions more or less correctly. Yes, in principle you could remove the pedals and seat of a moving bike, but that requires acrobatics – that’s why I hand out only 3 out of 5 gold stars.
- The Muse suggestion to remove the front wheel while riding is too dangerous for me: only one point
- Alexa provides an answer from a bicycle forum about how to fix a squeak. This is nonsense.
- Dear models, why not choose the bell?
3) Tough nuts to crack with logical reasoning and contextual understanding
Now it gets very, very difficult. I ask questions that even humans can’t answer easily.

A correct answer to the question would be that there is no exact data on this, or that there are probably about as many married men as married woman.
- AI21 is in principle correct about the second statement (there are indeed more men), but that is no logical reason for the first statement.
- All models except GPT-3 answer the question instinctively wrong and provide partly even questionable explanations.
- Even GPT-3 does not get the full score. The model does not provide any assessment or reference to missing publicly available information.
- Alexa’s answer of 6,6% is almost certainly wrong, but at least it goes in the right direction.
Final countdown – How do the new beasts among the transformers fare agains GPT-3?
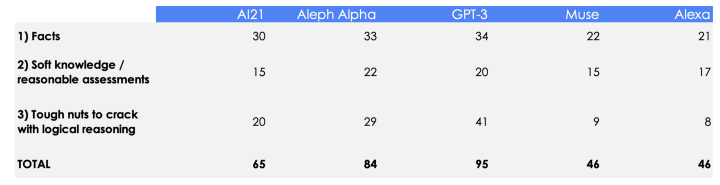
The result of my subjective test was partly unexpected:
- ALL models except Muse do better than Alexa in the field of general knowledge / logical reasoning. This does not mean that Alexa is stupid. After all, she represents the most elaborate voice-based assistance system. She can do many things like tell the time, play music, set a timer, give traffic information and a thousand other tasks that the LLM models listed above cannot even apprehend. However, she can do practically nothing that she was not explicitly programmed for.
- GPT-3 still leads among LLMs. GPT-3 not only performs better overall than all other models, but also cracks the toughest logical nut in the test. Amazing!
- AI21 and especially ALEPH ALPHA are catching up to GPT-3. ALEPH ALPHA in particular is doing very well, taking into account the lower funding. The model only made a few minor mistakes in the test. I believe that both models will be able to compete with GPT-3 in the upcoming months. This would profit all users, who then would have more freedom of choice.
Many thanks to: Kirsten Küppers, Hoa Le van Lessen and Almudena Pereira for inspiration and support with this post!
Stay tuned: My next tests will focus on how the models perform with business related issues.
Read the full article on medium.com/@maximilianvogel